Why are updates necessary and why are they paid?
A-Parser is constantly evolving. With the release of new versions, improvements and fixes are introduced. In this article, we will analyze what updates are, how they differ from the license, what role they play, and why it is necessary to pay for them.
License ≠ updates
By purchasing A-Parser, you receive a perpetual license for its use and 3-6 months of free updates depending on the purchased license. After the free updates period ends, you can update to the last available stable version and continue using the parser in full — as much as the version available at the time of the subscription expiration allows.
To renew your subscription, you can purchase one of three update packages: for 3 months, one year, and lifetime for $49, $149, and $399 respectively.
You do not need to pay for updates constantly. There is no need to pay for the period during which there was no update subscription.
Why are updates paid?
🐞 Bug fixes
Websites and various types of resources evolve quite rapidly. Any, even the most insignificant changes on the part of the target site can affect parsing. This happens because parsers are initially tailored to a specific structure, and changes in layout, protection, or other various internal mechanics lead to incorrect data in the results, their complete absence, and other errors. Parsing itself negatively affects the servers allocated for websites: requests and, accordingly, the load grow. Services losing profit are forced to look for a way out of this situation, which leads to the emergence of new types of protection and the development of old ones.
With each such change, it is necessary to make adjustments. Behind each one is an analysis of the problem, a search for a solution, and its implementation.
🧰 Every day, each built-in parser undergoes a system of internal tests. If the test requests are completed successfully, the resulting values are checked. A failed test signals errors present in the parser. Thanks to the tests, we respond promptly to breakages and immediately start working on fixing them.
Some of the most complex, in-demand, and therefore priority parsers for us are the Yandex and Google search engine parsers. Each consists of many parts solving a specific task. Among them are request preparation, header formation, obtaining the page source code, various types of result formatting, working with captcha, etc. All of this must be maintained in working condition. The parser provides for the presence of variables containing all the necessary data from the page: search results, advertisements, related keywords, and other values. They are extracted using regular expressions that assume the presence of a certain document structure on the page (order of elements, their types, classes, and other various attributes). In the event of a critical change in this structure, the regex that fit its previous version stops extracting the required fragment, and the parser is sent for revision.
✨ Improvements
In addition to maintaining the functionality of built-in parsers, with each release, new features are added and various improvements are made, affecting both performance and the quantity of data obtained. New parsers are included in the build, and new methods are implemented in the JavaScript API.
You can view all changes here.
Issues related to missing updates
The lack of timely updates causes incorrect operation of built-in parsers. The reasons can be different. For example, the page layout might have changed. A parser that has not received an update tries to collect data using old regular expressions not adapted to the new format. As a result, failed requests appear, various errors pop up, and there is no result.
Google parser example
A user contacted support with the following problem:
I am collecting Google search results with your proxies. 300 attempts are set for the request. All requests end up as failed. Everything was working yesterday.
At first glance, it seems that the problem is with the proxies, but tests with identical settings and requests on the latest version work successfully. This means the problem lies elsewhere. During the dialogue, it turns out that the user has an outdated version of A-Parser. This is the real reason for the incorrect operation of the Google parser.
Yandex parser example
In Yandex, the layout of pages with captcha changed, which is why it stopped being solved. A corresponding thread was created on the forum in the Tasks section.
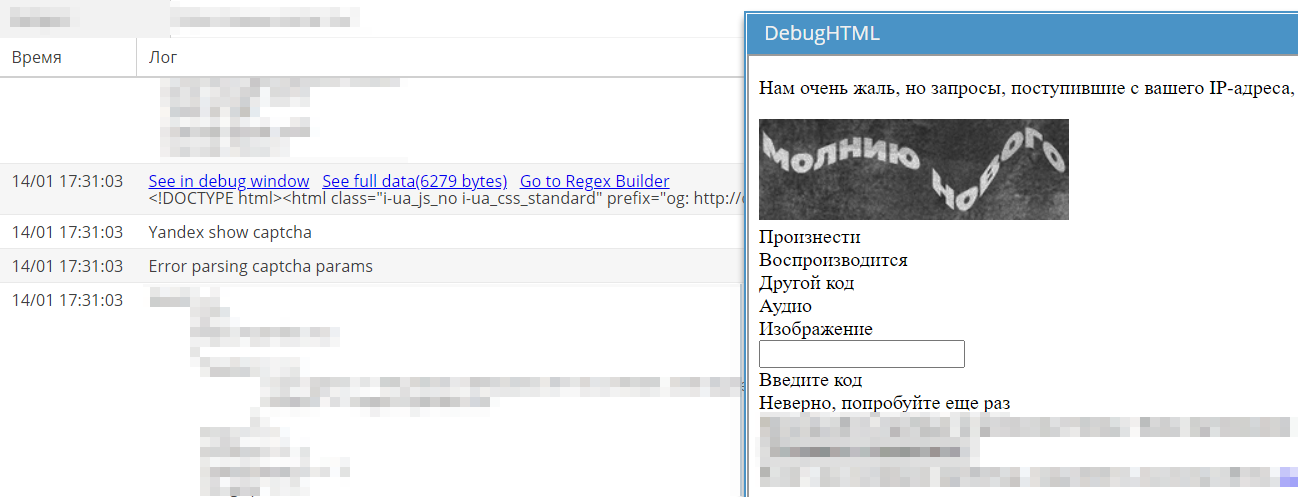
The fix was released the next morning. The task was closed and moved to the Next release section. This section contains threads for all fixes and improvements that will be included in the next stable version.
Accordingly, in an A-Parser that did not receive the fresh update, the captcha in Yandex was no longer solved.
Conclusion
By purchasing A-Parser, you receive a perpetual license to use the program and a package of free updates for a certain period. If necessary, after the subscription expires, you can renew it by purchasing one of the offered update packages.
Websites are unstable – parsers require constant adjustments and improvements. Maintaining their working condition is our job. A priority task on which we put great effort to release working fixes as quickly as possible. The cost of updates accounts for the labor behind them. Each release is not just a list of fixes and improvements – it is months of focused work by the A-Parser team.