Settings
A-Parser contains the following groups of settings:
- Global Settings - main program settings: language, password, update parameters, number of active tasks
- Threads settings - settings for threads and deduplication methods for tasks
- Parser settings - the ability to configure each individual parser
- Proxy check settings - number of threads and all settings for the proxy checker
- Additional settings - optional settings for advanced users
- Task presets - saving tasks for later use
All settings (except global and additional) are saved in so-called presets - sets of pre-saved settings, for example:
- Different settings presets for the
 SE::Google parser - one for parsing links with a maximum depth of 10 pages of 100 results each, another for assessing competition for a query, parsing depth 1 page of 10 results
SE::Google parser - one for parsing links with a maximum depth of 10 pages of 100 results each, another for assessing competition for a query, parsing depth 1 page of 10 results - Different proxy checker setting presets - separate for HTTP and SOCKS proxies
For all settings, there is a default preset (default), it cannot be changed; all changes must be saved in presets with new names.
Global settings
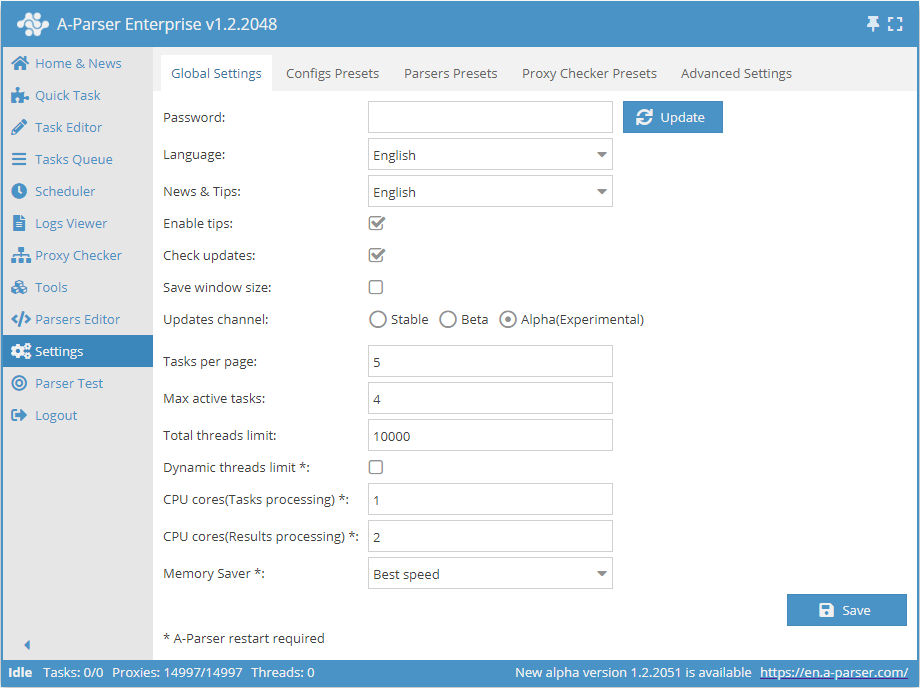
| Parameter name | Default value | Description |
|---|---|---|
| Password | No password | Set a password to log into A-Parser |
| Language | English | Interface language |
| News and tips | English | Language for news and hints |
| Enable tips | ☑ | Determines whether to display hints |
| Check for updates | ☑ | Determines whether to display information about the availability of a new update in the Status bar |
| Save window size | ☐ | Determines whether to save the window size |
| Update channel | Stable | Selection of the update channel (Stable, Beta, Alpha) |
| Tasks per page | 5 | Number of tasks per page in the Task Queue |
| Max active tasks | 1 | Maximum number of active tasks |
| Total thread limit | 10000 | Total thread limit in A-Parser. A task will not start if the total thread limit is less than the number of threads in the task |
| Dynamic thread limit | ☐ | Determines whether to use the Dynamic thread limit |
| CPU cores (task processing) | 2 | Support for processing tasks on different CPU cores (Enterprise license only). Described in detail below |
| CPU cores (result processing) | 4 | Multiple cores are used only during filtering, Results Builder, Parse custom result (all license types) |
| Memory Saver | Best speed | Allows determining how much memory the parser can use (Best speed / Medium memory usage / Save max memory). Read more... |
CPU cores (task processing)
Support for processing tasks on different CPU cores; this feature is available only for the Enterprise license
This option speeds up (many times over) the processing of several tasks in the queue (Settings -> Max active tasks), but it does not speed up the execution of a single task in any way
Intelligent distribution of tasks across working cores based on the CPU load of each process is also implemented The number of CPU cores used is set in the settings; the default is 2, the maximum is 32
As with threads, it is better to approach the choice of the number of cores experimentally; reasonable values would be 2-3 cores for 4-core processors, 4-6 for eight-core processors, etc. It is worth considering that with a large number of cores and high load, 100% load of the main control process (aparser/aparser.exe) may occur, at which point a further increase in processes for task processing will only cause a general slowdown or unstable operation. It is also worth considering that each task processing process can create an additional load of up to 300% (i.e., load 3 cores simultaneously at 100% each); this feature is related to multi-threaded garbage collection in the JavaScript v8 engine
Thread settings
The operation of A-Parser is built on the principle of multithreaded data processing. The parser performs tasks in parallel in separate threads, the number of which can be flexibly varied depending on the server configuration.
Description of thread operation
Let's look at what threads are in practice. Suppose you need to prepare a report for three months.
Option 1
You can prepare the report first for the 1st month, then for the 2nd, and then for the 3rd. This is an example of single-threaded work. Tasks are solved one by one.
Option 2
Hire three accountants who will each prepare a report for one month. Then, after receiving the results from all three, make a general report. This is an example of multithreaded work. Tasks are solved simultaneously.
As seen from these examples, multithreaded work allows a task to be completed faster, but at the same time requires more resources (we need 3 accountants instead of 1). Multithreading works similarly in A-Parser. Suppose you need to parse information from several links:
- with one thread, the application will parse each site one by one
- when working in several threads, each will process its own link, and upon completion, will proceed to the next unprocessed one in the list
Thus, in the second option, the entire task will be completed significantly faster, but it requires more server resources, so it is recommended to follow the System requirements
Thread settings
Thread settings in A-Parser are configured separately for each task, depending on the parameters required for its execution. By default, 2 thread configs are available: for 20 and 100 threads, for default and 100 Threads respectively.
To access the settings of the selected config, you need to click on the pencil icon ![]() , after which its settings will open.
, after which its settings will open. 
You can also go to the thread settings via the menu item: Settings -> Threads settings
Here we can:
- create a new config with your own settings and save it under its own name (Add new button)
- make changes to an existing config by selecting it from the drop-down list (Save button)
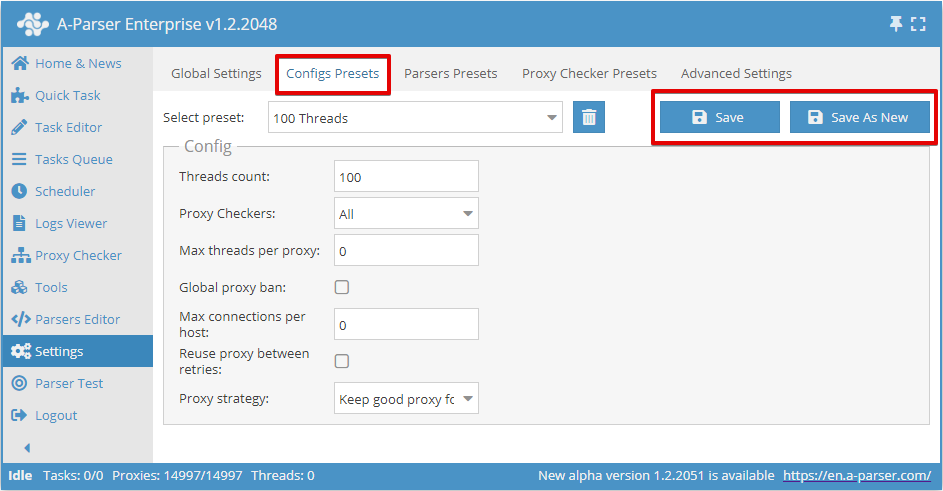
Threads count
This parameter sets the number of threads in which the task launched with this config will work. The number of threads can be any, but you need to consider the capabilities of your server, as well as the proxy plan limit, if such a limit is provided. For example, for our proxies, you can specify no more than the selected plan.
It is also important to remember that the total number of threads in the parser is equal to the sum of running tasks and enabled proxy checkers with proxy verification. For example, if one task is running at 20 threads and two tasks at 100 threads each, and one proxy checker is also running with proxy verification enabled at 15 threads, then in total the parser will use 20+100+100+15=235 threads. At the same time, if the proxy plan is designed for 200 threads, there will be many failed requests. To avoid them, you need to lower the number of threads used. For example, disable proxy verification (if it is not needed, this will save 15 threads) and lower the number of threads in one of the tasks by another 20 threads. Thus, for one of the running tasks, you need to create a config for 80 threads, leaving the others as they are
Proxy Checkers
This parameter allows choosing a proxy checker with specific settings. Here you can select the All parameter, which means using all running proxy checkers, or only those that need to be used in the task (multiple positions can be selected)
This setting allows running a task only with the required proxy checkers. The proxy checker configuration process is discussed here
Max threads per proxy
This sets the maximum number of threads in which the same proxy will be used simultaneously. It allows setting different parameters, for example, 1 thread = 1 proxy operation.
By default, this parameter is 0, which disables this function. In most cases, this is sufficient. But if you need to limit the load on each proxy, then it makes sense to change the value
Global proxy ban
All tasks launched with this option have a shared proxy ban database. The feature of this parameter is that the list of banned proxies for each parser is common to all running tasks.
For example, a proxy banned in SE::Google in task 1 will also be banned for SE::Google in task 2, but it can still work freely in  SE::Yandex in both tasks
SE::Yandex in both tasks
Max connections per host
This parameter indicates the maximum number of connections per host, intended to reduce the load on a site when parsing information from it. Essentially, specifying this parameter allows controlling the number of requests at one moment for each specific domain. Enabling this parameter applies to the task; if you run several tasks simultaneously with the same thread config, the limit will be calculated for all tasks.
By default, this parameter has a value of 0, i.e., it is disabled.
Reuse proxy between retries
This setting disables the proxy uniqueness check for each retry, and proxy banning will also not work. This, in turn, means the ability to use 1 proxy for all retries.
This parameter is recommended to be enabled, for example, in cases where it is planned to use 1 proxy, where the output IP changes with each connection.
Proxy strategy
Allows managing the proxy selection strategy when using sessions: keep the proxy from a successful request for the next request or always use a random proxy.
Recommendations
This article covers all settings that allow managing threads. It is worth noting that when configuring the thread config, it is not necessary to set all the parameters mentioned in the article; it is enough to set only those that will ensure a correct result. Usually, you only need to change the Threads count, other settings can be left at default.
Parser settings
Each parser has many settings and allows saving different sets of settings into presets. The preset system allows using the same parser with different settings depending on the situation, let's look at an example with the SE::Google parser:
Preset 1: "Parsing maximum number of links"
- Pages count:
10 - Links per page:
100
Thus, the parser will collect the maximum number of links by going through all pages of the search results
Preset 2: "Parsing competition by query"
- Pages count:
1 - Links per page:
10 - Results format:
$query: $totalcount\n
In this case, we get the number of search results for the query (query competition) and for greater speed, it is enough for us to parse only the first page with a minimum number of links
Creating presets
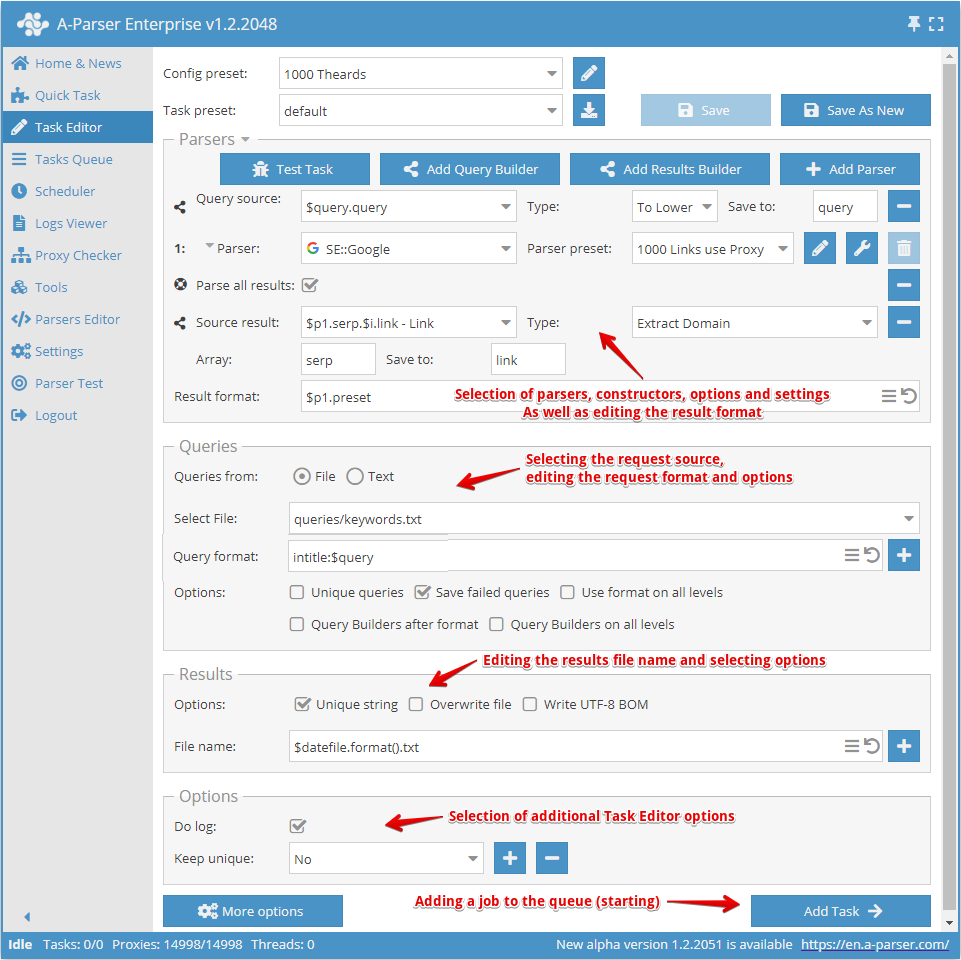
Creating a preset starts with selecting the parser/parsers and defining the result that needs to be obtained.
Next, you need to understand what the input data will be for the selected parser; in the screenshot above, the SE::Google parser is selected, its input data is any strings as if you were searching for something in a browser. You can select a query file or enter queries into the text field.
Now you need to override the settings (select options) for the parser, add deduplication. You can use the Query Builder if you need to process queries. Or use the Results Builder if you need to process the results in some way.
Next, you should pay attention to editing the result filename, and change it at your discretion if necessary.
The last point is selecting additional options, especially the Enable log option. Very useful if you want to find out the reason for a parsing error.
After all this, you need to save the preset and add it to the Task Queue.
Overriding settings
Override preset - quick overriding of settings for the parser, this option can be added directly in the Task Editor. You can add several parameters in one click. The settings list shows default values, and if an option is highlighted in bold, it means it is already overridden in the preset
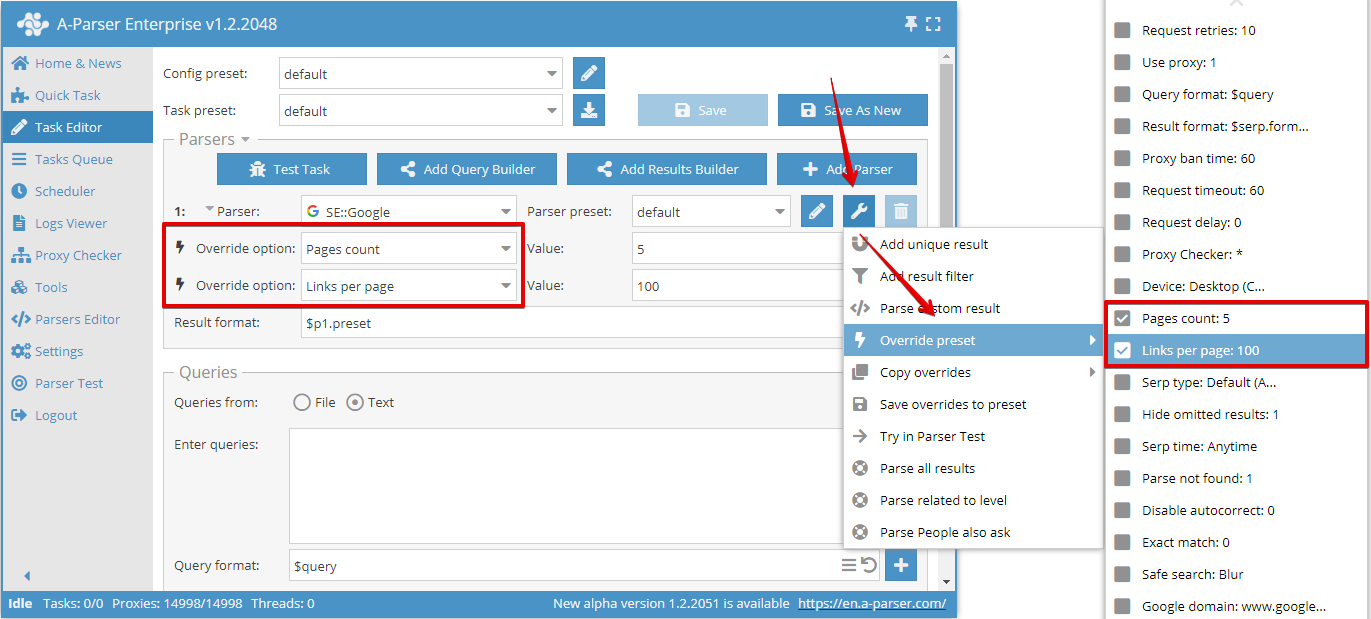
In this example, two options are overridden: Pages count was set to 5 and Links per page was set to 100.
You can use an unlimited number of Override preset options in a task, but if there are many changes, it is more convenient to create a new preset and save all changes into it.
You can also easily save overrides using the Save overrides to preset function. They will be saved as a separate preset for the selected parser.
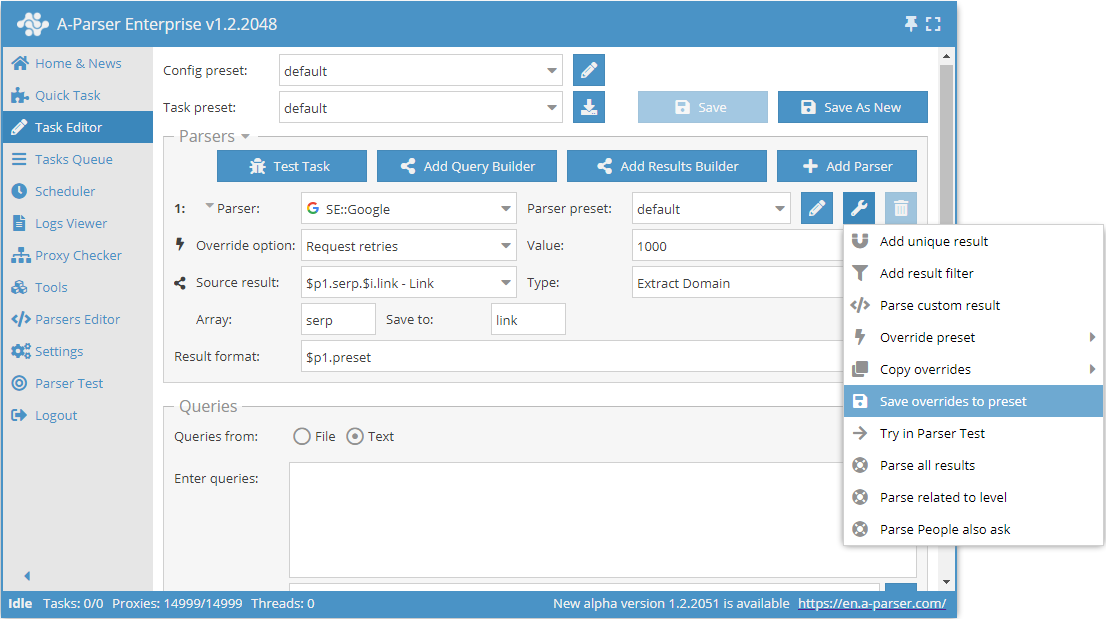
After which, in the future, it is enough to simply select this saved preset from the list and use it.
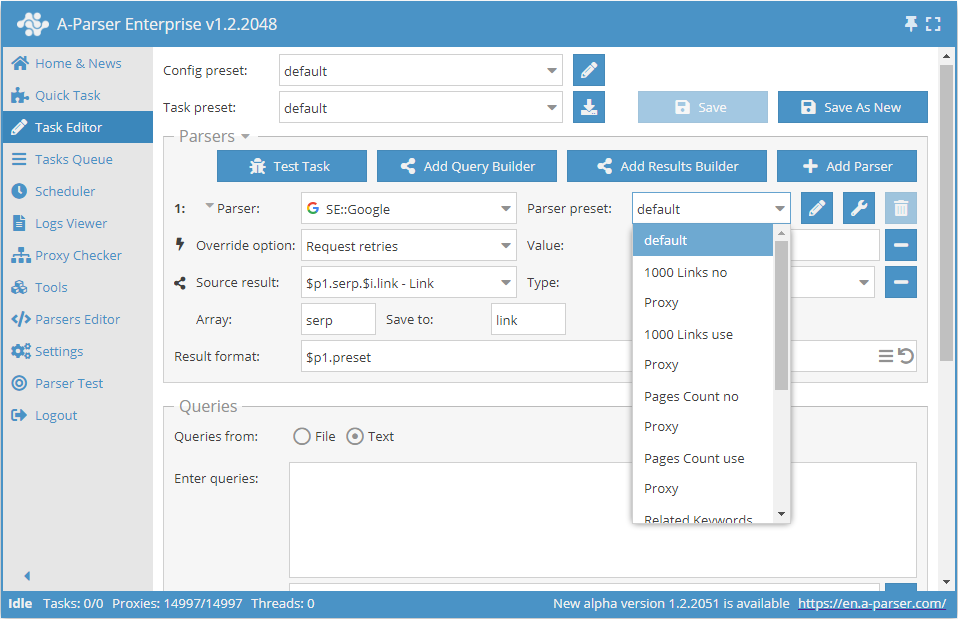
Common settings for all parsers
Each parser has its own set of settings; you can find information on the settings of each parser in the corresponding section
In this table, we have presented common settings for all parsers
| Parameter name | Default value | Description |
|---|---|---|
| Request retries | 10 | Number of attempts for each request; if the request cannot be completed in the specified number of attempts, it is considered failed and skipped |
| Use proxy | ☑ | Determines whether to use a proxy |
| Query format | $query | Query format |
| Result format | Each parser has its own value | Result output format |
| Proxy ban time | Each parser has its own value | Proxy ban time in seconds |
| Request timeout | 60 | Maximum request timeout in seconds |
| Request delay | 0 | Delay between requests in seconds; you can specify a random value in a range, for example, 10,30 - delay from 10 to 30 seconds |
| Proxy Checker | All | Proxies from which checkers should be used (choice between all or listing specific ones) |
Common for all parsers working over HTTP protocol
| Parameter name | Default value | Description |
|---|---|---|
| Max body size | Each parser has its own value | Maximum size of the results page in bytes |
| Use gzip | ☑ | Determines whether to use compression for transmitted traffic |
| Extra query string | Allows specifying additional parameters in the query string |
Default settings for each parser may differ. They are stored in the default preset in the settings of each parser.
Proxy checker settings
Read more about Proxy checker configuration
Additional settings
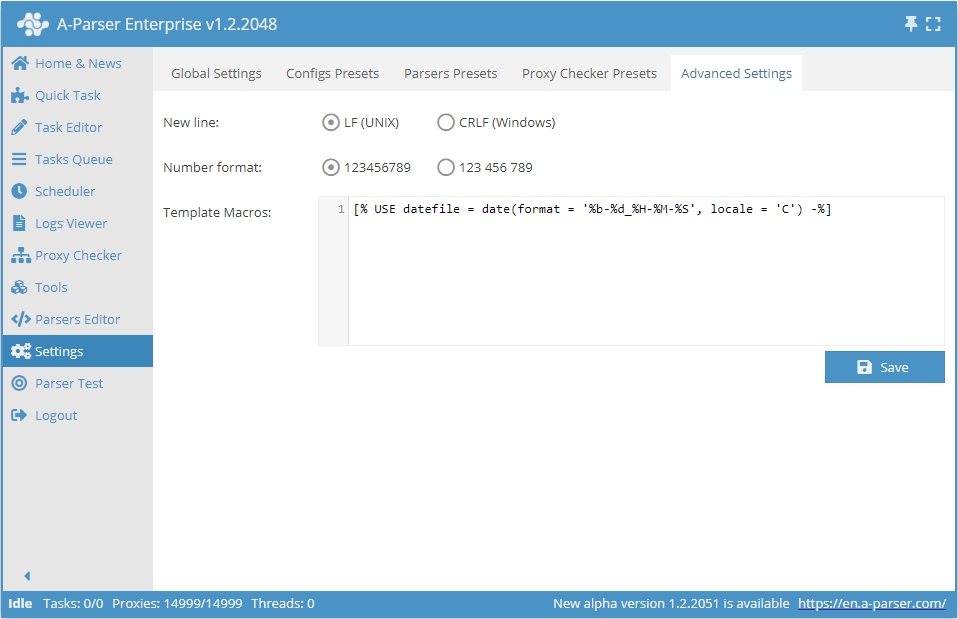
- Line break allows choosing between Unix and Windows line ending variants when saving results to a file
- Number format - sets how to display numbers in the A-Parser interface
- Template macros