Results deduplication
Deduplication, unique results, removing duplicates, removing repeats - all this implies that we do not need repeating results. In A-Parser there are 2 methods of deduplication, let's examine each in detail.
Deduplication by string
This method works after result formatting; immediately before writing the result to a file, each line is checked for uniqueness, and only new unique lines are written to the file.
See also: Order of processing requests
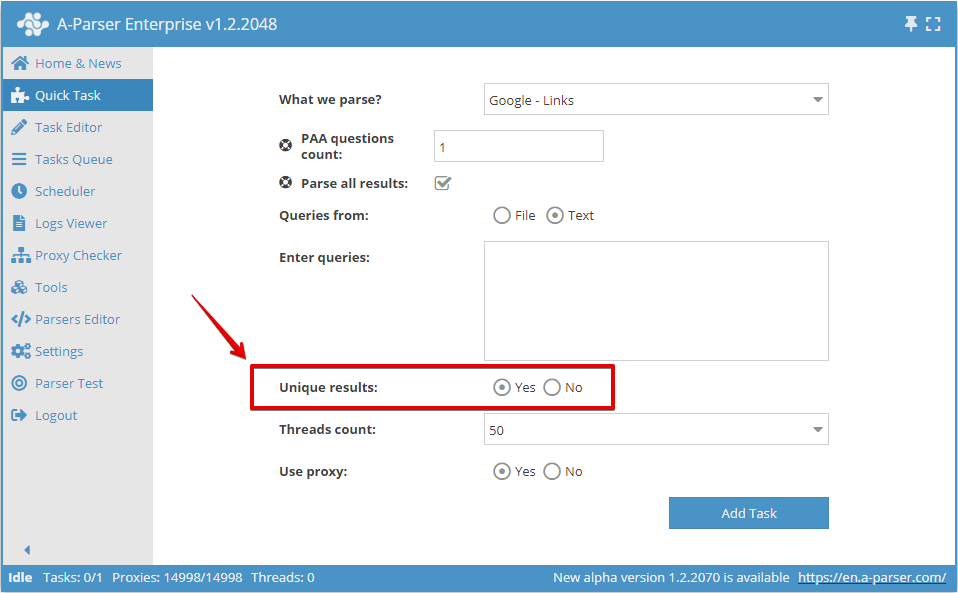
You can enable deduplication by string in the Quick Task:
Or in the Task Editor:
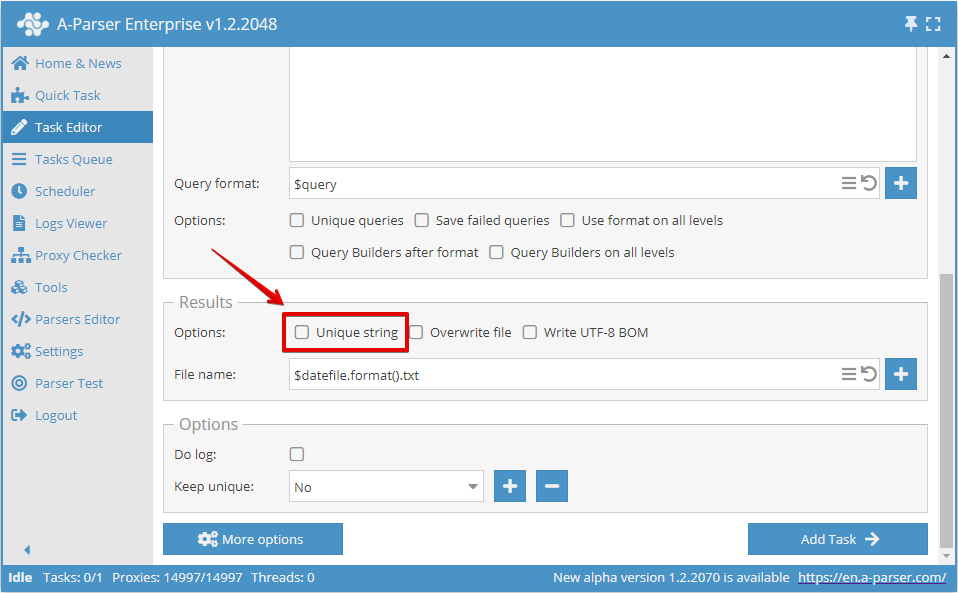
Deduplication by any result
Deduplication by any result allows you to perform deduplication directly on a selected result from a specific parser. You can add this deduplication type in the Task Editor by clicking on the tool icon to the right of the parser and clicking Add unique result:
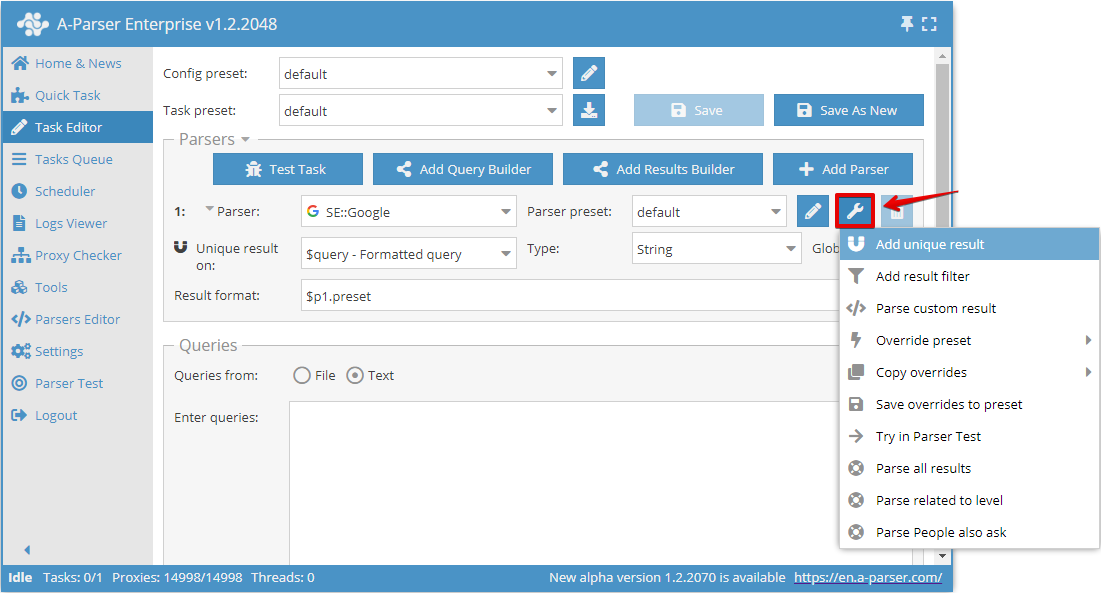
Now you can choose which result to perform deduplication on and the deduplication type:
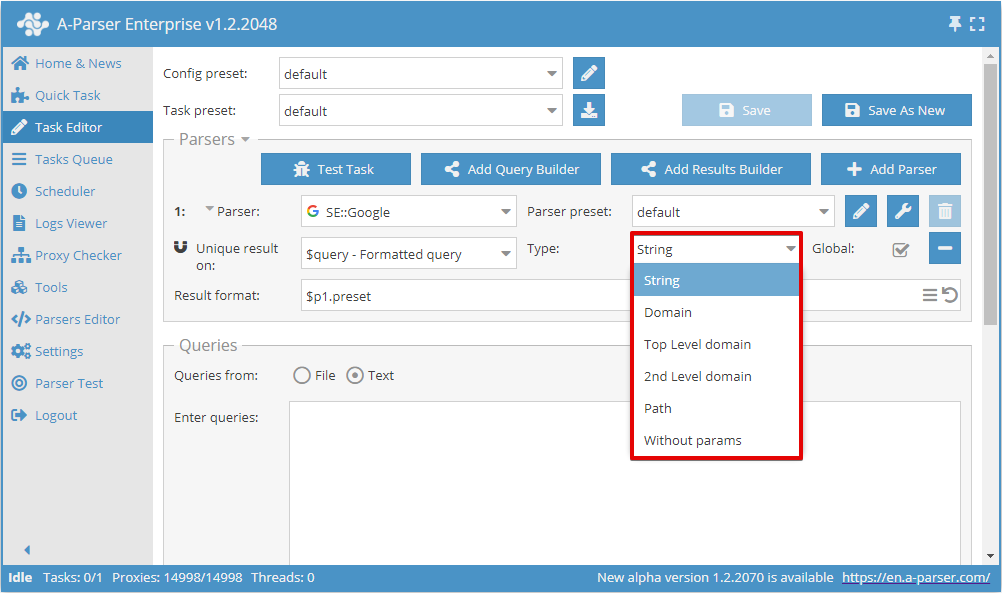
The Global toggle is used when 2 or more parsers are selected; it determines whether to perform common deduplication or separately for each parser.
Deduplication types
| Parameter | Description |
|---|---|
| String | Deduplication by string (the entire result string is compared) |
| Domain | Deduplication by domain (the entire domain is compared, e.g., www.domain.com and domain.com are different domains) |
| Top-level domain | Deduplication by main domain considering regional, commercial, educational, and other domains (e.g., domain.co.uk and domain2.co.uk are different domains, while sub1.domain.com and sub2.domain.com are the same) |
| 2nd-level domain | Deduplication by 2nd-level domain (second-level domains are compared, e.g., www.domain.com, domain.com, and user.subdomain.domain.com are all the same domain) |
| Path | Deduplication by path (link parts up to the file are compared, e.g., http://domain.com/path1/file.php and http://domain.com/path1/file2.php have the same link parts up to the file) |
| Without parameters | Deduplication by link without parameters (links without parameters are compared, e.g., http://domain.com/file.php?page=1 and http://domain.com/file.php?page=2 are the same links) |
Query deduplication
Query deduplication sends only unique queries to parsing that have not been parsed previously in the current task. Main use cases:
- If there are duplicates in the source queries and it is undesirable to parse them (double work)
- When using the Parse to level option, it is necessary to use only unique queries to prevent query expansion and looping (for example, when using the
 HTML::LinkExtractor parser)
HTML::LinkExtractor parser)
In all other cases, unnecessary use of query deduplication will only slow down the overall parser performance
Saving deduplication state across tasks
It is possible to save the deduplication database for use in future tasks, which allows saving only new unique results in new tasks (for example, links when parsing SERPs in  SE::Google)
SE::Google)
To save the deduplication database, you must create a new database name when adding the first task:
For all subsequent tasks, you must select the previously created database name; this way, only new unique results will be saved, regardless of whether the results are written to the same file as in the first task or to a new file.