Query processing order
In A-Parser, there are many functions and capabilities; this diagram represents the request processing order from reading it from a file (or text) to saving the final result to a file.
Schematic request processing order
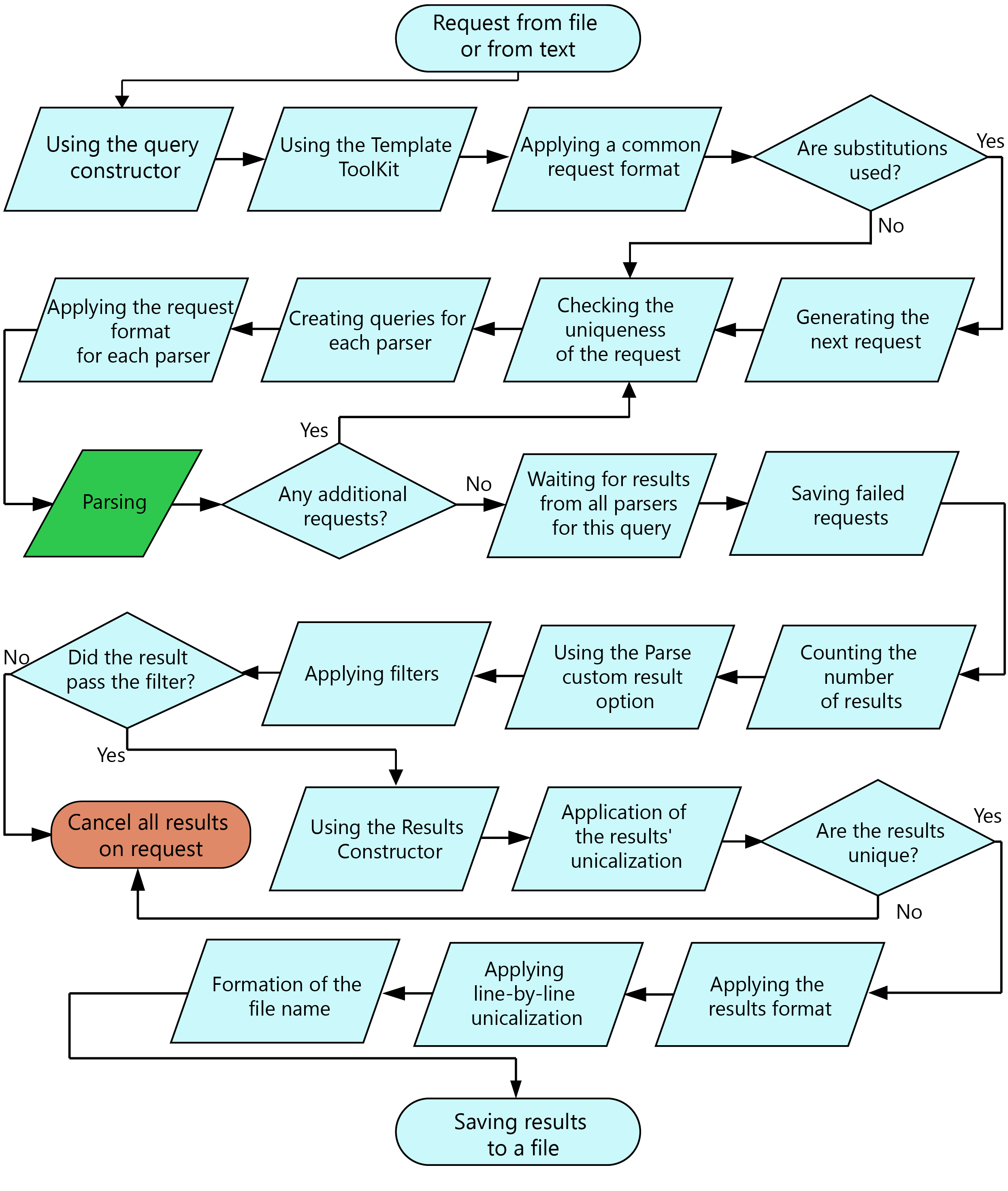
Notes
- When filtering and deduplicating results, the query and its results are canceled entirely if a simple result is used for comparison; if an array is used in the comparison, elements are removed from that array.
- Many steps in the diagram are optional and depend on the settings specified in the Task Editor.
- Additional queries may appear when using the Parse all result and Parse to level options. All additional queries have the next level relative to the query from which the additional queries were created; level counting starts from zero, i.e., the original queries from a file or text always have level 0. Queries after applying substitutions also have level 0.
Failed queries
A query is considered failed and is skipped if it could not be completed within the specified number of attempts.
How to determine why a query failed? Enable logging or run a Task Test. All errors are logged. By examining the log, you can understand what went wrong.
Example of a failed query. The logs suggest that the query could not be completed due to a captcha, and the attempts have run out. In this case, connecting a solving service or increasing the number of attempts may help (only if you are parsing with proxies; otherwise, increasing attempts is useless).
How to increase the number of attempts? You need to override the option Request retries and set a higher value.