Results Builder
Results Builder - allows you to transform results from each parser before formatting and saving them to disk
Capabilities
- Splitting the result into parts using a regular expression or an arbitrary delimiter
- Substring replacement in the result or replacement by regular expression
- Extracting a domain or main domain from a link
- Converting the result to upper\lower case
- Removing HTML tags (
<b>text</b>->text) - Converting HTML entities to their Unicode equivalents (
©->©) - Retrieving data using XPath queries
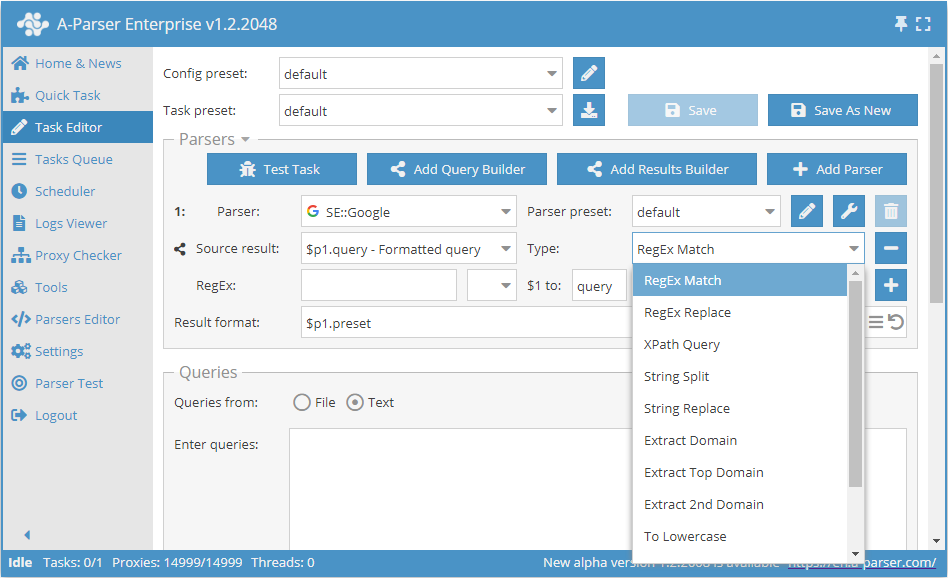
Examples
Domains parsing
Saving only domains when parsing links from search engines:
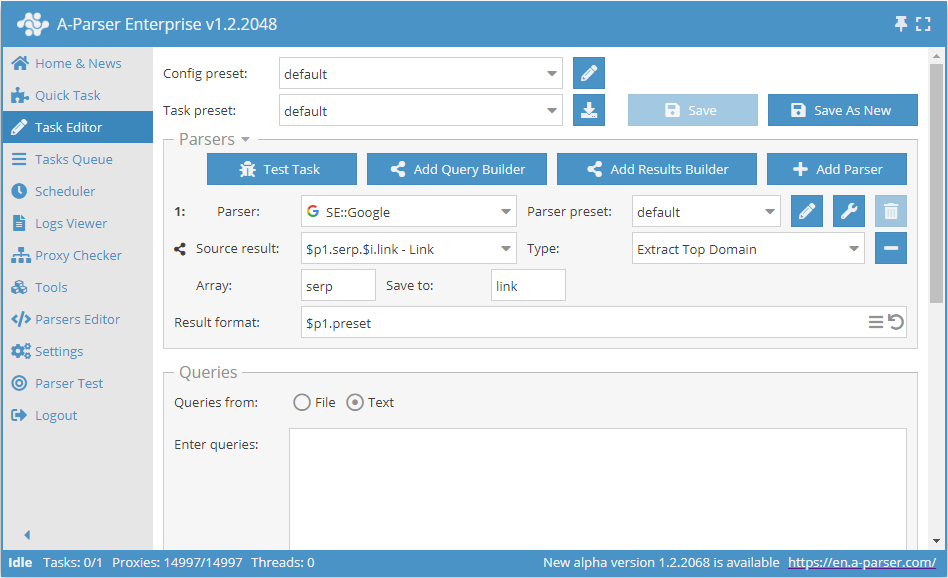
The source used is the link elements from the serp array from the first parser; the function for extracting the main domain from a link will be applied to each element, and the new result will be saved under the same name (link element in the serp array) - therefore, changing the result format is not required
Snippet parsing with cleaning
Saving snippets from search engines with cleaning of HTML tags and conversion of HTML entities
By default, anchors and snippets are parsed with all nested tags, which allows preserving the same formatting as when viewing search engine results. If only plain text is needed, you can use the capabilities of the Results Builder:
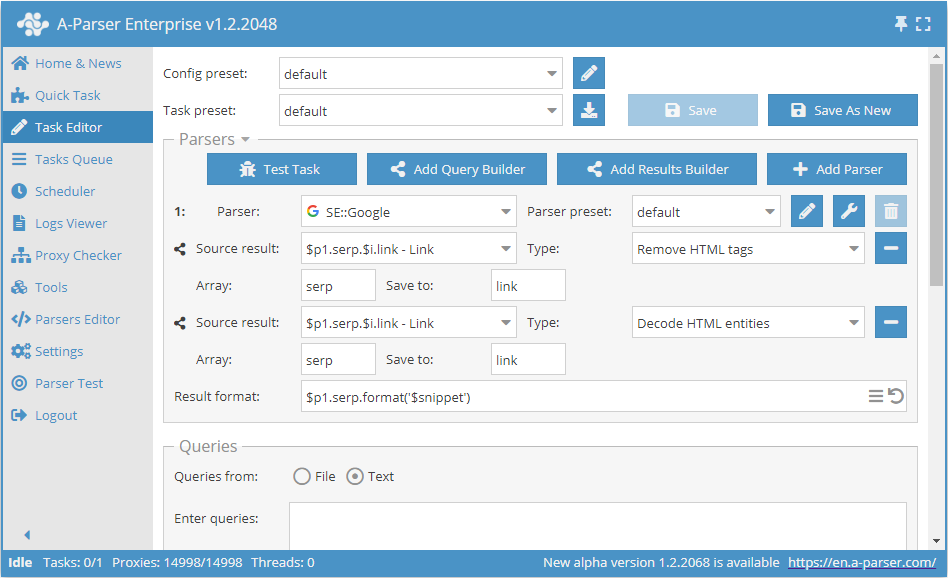
In this example, two Results Builders are applied sequentially to the snippets - removing HTML tags and converting HTML entities
Parsing using XPath
Parsing links from search results using XPath:
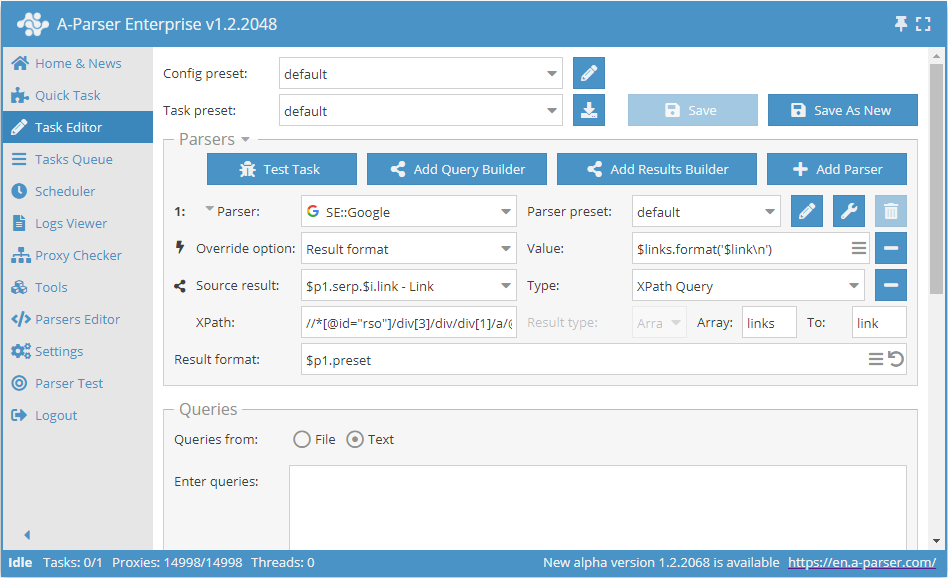
This example shows parsing links from the Google search engine. The following XPath query is used:
//*[@id="rso"]/div[3]/div/div[1]/a/@href