Frequently Asked Questions
1. Questions related to demo, payment, and purchase
1.1. How to download results in the Demo version?
In the Demo version, results are not available for download. We provide them upon your request. Send us your queries and specify which parser you are interested in, and we will send you the results (the quantity is limited within the demo).
1.2. Do I need to pay extra for anything after purchasing A-Parser?
No. More details: licenses and add-ons, purchase page.
1.3. Where and how can I pay for proxies?
When purchasing a license, you are provided with bonus proxies.
Lite - 20 threads for 2 weeks, Pro and Enterprise - 50 threads for a month.
You can buy more threads or renew them in the Members Area on the Shop tab, Proxy sub-section.
1.4. Could you set up a task for me for money?
Technical support for questions related to A-Parser operation is provided free of charge. Regarding paid assistance in creating tasks, you can contact here: Paid services for creating tasks, help with configuration and A-Parser training.
1.5. Can I make a payment for the parser via Privat24 bank? Via KIWI?
The list of payment systems we work with is specified here: buy A-Parser.
1.6. If I only need to scrape the number of indexed pages in Yandex, which parser should I buy?
For such purposes, the Lite version is sufficient, but Pro is more practical and flexible in operation.
1.7. Where can I see my license details?
1.8. Is it possible to use purchased proxies from several IPs?
No.
2. Installation, launch, and update questions
2.1. I click on the Download button - but the archive is not downloading. What to do?
Check if you have free space on your hard drive, disable antivirus. Follow the installation instructions. Also check out How to start working.
2.2. I bought the Enterprise version, but PRO is still being installed. What to do?
Delete the previous version. In the Members Area, check if your IP address is correctly specified. Before downloading, click the Update button. Download the newer version. More details in the installation instructions.
2.3. I installed the program, but it doesn't start, what to do?
Check running applications, disable antivirus, check available free RAM. Also, in the Members Area, check if your IP address is correctly specified. More details: installation instructions.
2.4. What to do if I have a dynamic IP address?
It's okay, A-Parser supports working with dynamic IP addresses. Just every time it changes, you need to specify it in the Members Area. To avoid these manipulations, it is recommended to use a static IP address.
2.5. What are the optimal server/computer parameters for installing the parser?
All system requirements can be viewed here: system requirements.
2.6. I started a task. The parser crashed and won't start anymore, what to do?
You need to stop the server, check if the process is still in memory, and try to start it again. You can also try to start A-Parser with all tasks stopped. To do this, run it with the -stoptasks parameter. Details about starting with a parameter.
2.7. What password should I enter when opening the address 127.0.0.1:9091?
If this is the first launch, the password is empty. If not the first - then the one you set. If you forgot the password - password reset.
2.8. I enter my IP in the Members Area, but it doesn't change in the Your current IP field. Why?
The Your current IP field displays the IP that is currently valid for you, and it should not change. This is the one you should enter in the IP 1 field.
2.9. Can I run two copies simultaneously?
You can run two copies on one machine only if they have different ports specified in the configuration file.
You can run two A-Parsers on different machines simultaneously only if you have purchased an additional IP in the Members Area.
2.10. Does the parser have a hardware binding?
No. Your IP is used for license control.
2.11. Question about update - should I update only .exe? config/config.db and files/Rank-CMS/apps.json - what are these files for?
Unless otherwise specified, update only .exe. The first file is for storing A-Parser configuration, and the second is the database for CMS detection and the actual operation of the ![]() Rank::CMS parser.
Rank::CMS parser.
2.12. I have Win Server 2008 Web Edition - the parser won't start...
A-Parser will not work on this OS version. The only option is to change the OS.
2.13. I have a 4-core processor. Why does A-Parser use only one core?
A-Parser uses from 2 to 4 cores; additional cores are used only during filtering, Results Builder, and Parse custom result.
2.14. I started getting a segmentation error (segmentation failed, segmentation error). What to do?
Most likely your IP has changed. Check in the Members Area.
2.15. I have Linux. A-Parser started, but it doesn't open in the browser. How to solve?
Check the firewall - most likely it is blocking access.
2.16. I have Windows 7. A-Parser started, but it doesn't open in the browser and there is no Node.js process in the task manager. How to solve?
You need to check Windows updates and install the latest available ones. Specifically, you need the Windows 7 SP1 update.
2.17. A-Parser doesn't start and FATAL: padding_depad failed: Invalid argument provided. at ./Crypt/Mode/CBC.pm line 20 error is written in aparser.log.
Most likely a problem occurs with some task (/config/tasks/ folder) due to a disk error (for example, if the PC power was turned off without a proper shutdown); more details can be found if you run A-Parser with the -morelogs flag.
Solution: start A-Parser with the -stoptasks parameter. If it didn't help, then clear the entire /config/tasks/. If the problem persists after this, then install the parser again in a new directory and move the config from the old one (if it is not corrupted).
3. Questions about main settings and other settings
3.1. How to set up the proxy checker?
Detailed instructions are located here: proxy settings.
3.2. No live proxies - why?
Check your internet connection, as well as the correctness of the proxy checker settings. If everything is done correctly, it means that your proxy list currently contains no working servers. The solution to this problem: either use other proxies or try again later. If you are using our proxies, check the IP address in the Members Area in the Proxies section. It is also possible that your provider is blocking access to other DNS; try the steps described here: http://a-parser.com/threads/1240/#post-3582
3.3. How to connect antigate?
Detailed instructions for setting up antigate here.
3.4. I changed parameters in the parser settings, but they were not applied. Why?
The default preset cannot be changed; if any changes are made, you need to click Save as new preset, and then use it in your task.
3.5. Can I change the settings of a running task?
You can, but not all of them. In a running task, you can click pause and select Edit in the dropdown menu there.
3.6. How to import a preset?
Click the button next to the task selection field in the Task Editor. Details here.
3.7. How to configure the parser so it doesn't use proxies?
In the settings of the required parser, uncheck Use proxy.
3.8. I don't have the Add override / Override option button!
This option can be added directly in the Task Editor. Parser options.
3.9. How to overwrite to the same result file?
When creating a task, set the Overwrite file option.
3.10. Where to change the password for the parser?
3.11. I put 6 million keys for parsing, also specified that all domains should be unique. How can I make it so that when I put new 6 million keys, only unique domains not intersecting with the previous parsing are recorded?
You need to use the Keep unique option when creating the first task and specify the saved database in the second one. Details in Additional options of task editor.
3.12. How to bypass the 1000 results limit for Google?
Use the Parse all results option.
3.13. How to bypass the 1024 threads limit on Linux?
3.14. What is the thread limit on Windows?
Up to 10,000 threads.
3.15. How to make queries unique?
Use the Unique queries option in the Queries block in the Task Editor.
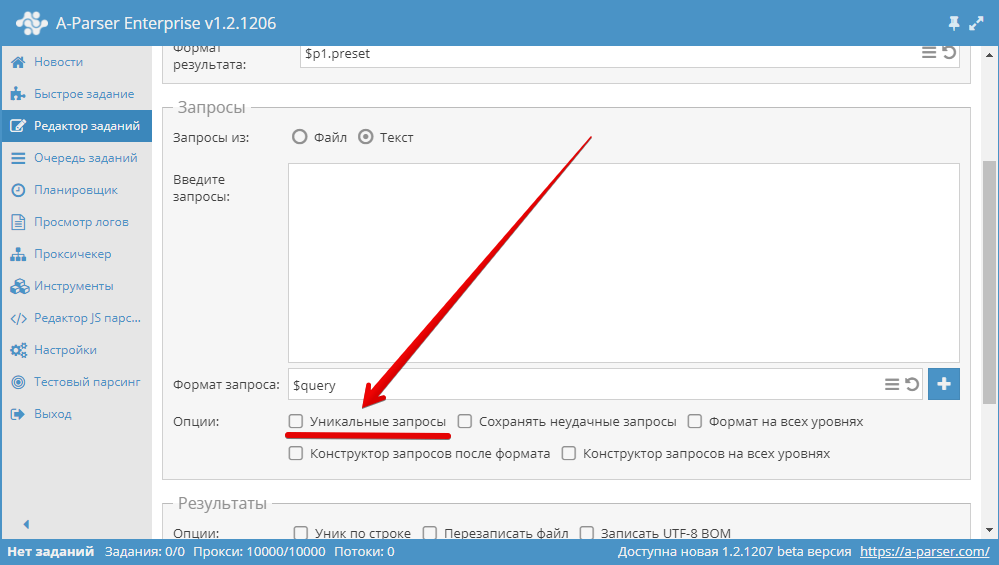
3.16. How to disable proxy checking?
In Settings - Proxy Checker Settings, select the required proxy checker and check the No check proxies box. Save and select the saved preset.
3.17. What is Proxy ban time? Can I set it to 0?
Proxy ban time in seconds. Yes, you can.
3.18. What is the difference between Exact Domain and Top Level Domain in the  SE::Google::Position parser
SE::Google::Position parser
Exact Domain is a strict match, i.e., if the output is www.domain.com and we are looking for domain.com, there will be no match. Top Level Domain checks the entire top domain, i.e., there will be a match here.
3.19. If I run a test parse - everything works, if a regular one - I get a Some error.
Most likely the problem is in DNS; try to follow these DNS configuration instructions.
3.20. Where is the Result Format set?
3.21. Dutch language is missing in  SE::Google, although it is available in Google settings. Why?
SE::Google, although it is available in Google settings. Why?
The Dutch language is Dutch, it is in the list. Details in the improvement on adding the Dutch language.
4. Questions about scraping and errors
4.1. What are threads?
All modern processors can perform tasks in multiple threads, which significantly increases the speed of their execution. For comparison, you can take a regular bus that carries a certain number of people per unit of time - this would be regular, single-threaded processing, and a double-decker bus that carries twice as many people in the same time - this would be multi-threaded processing. A-Parser can process up to 10,000 threads simultaneously.
4.2. Task won't start - says Some Error - why?
Check the IP address in the Members Area.
4.3. All queries go to failed, what to do?
Most likely the task is composed incorrectly or an incorrect query format is used. Also check if there are live proxies. You can also try increasing the Request retries option (more details here: failed requests).
4.4. How many accounts need to be registered to parse 1,000,000 keywords with  SE::Yandex::Wordstat?
SE::Yandex::Wordstat?
It is impossible to say exactly how many accounts are needed, as an account may stop being valid after an unknown number of requests. However, you can always register new accounts using the  SE::Yandex::Register parser or simply add existing accounts to the file files/SE-Yandex/accounts.txt.
SE::Yandex::Register parser or simply add existing accounts to the file files/SE-Yandex/accounts.txt.
4.5. Task won't start, says Error: Lock 100 threads failed(20 of limit 100 used) what to do?
It is necessary to increase the maximum available number of threads in the parser settings, or decrease it in the task settings. Details in Settings.
4.6. Can I run 2 tasks simultaneously?
Yes, A-Parser supports running multiple tasks simultaneously. The number of simultaneously running tasks is regulated in Settings - General Settings: Maximum active tasks.
4.7. Where is the result file located?
On the Tasks queue tab, after each task is finished, you can download the results. Physically they are located in the results folder.
4.8. Can I download the result file if parsing is not finished?
No, while the parsing is not finished, the results cannot be downloaded. But they can be copied from the aparser/results folder when the task is stopped or on pause.
4.9. Can your parser scrape 1,000,000 links for one query?
Yes, using the Parse all results option.
4.10. Is it possible to parse  Rank::CMS,
Rank::CMS,  Net::Whois without proxies?
Net::Whois without proxies?
Net::Whois - not advisable.4.11. How to scrape links from Google?
It is necessary to use SE::Google.
4.12. Can the parser follow links?
Yes, the  HTML::LinkExtractor parser can do this when using the Parse to level option.
HTML::LinkExtractor parser can do this when using the Parse to level option.
4.13. Google parses very slowly, what to do?
First of all, you should check the task logs; it is possible that all requests are failing. If so, you need to find the reason why the requests are failing and fix it. When parsing with SE::Google, failed attempts in the task logs are often related to Google showing captchas, which is normal. You can connect Anti-Captcha to bypass captchas so that the parser does not cycle through attempts.
Also, there is an article describing the factors that affect parsing speed and how they affect it: speed and principle of parser operation.
4.14. Can your parser scrape links where the text is only in Japanese?
Yes, to do this, you need to set the required language in the parser settings and also use Japanese keywords.
4.15. Can your parser scrape links only in the .de or .ru domain zone?
Yes. To do this, you need to use a filter.
4.16. How to get each result in the file from a new line?
When formatting the result, use \n. Example:
$serp.format('$link\n')
4.17. How to scrape top 10 sites from Google?
Here is the preset:
eyJwcmVzZXQiOiJUT1AxMCIsInZhbHVlIjp7InByZXNldCI6IlRPUDEwIiwicGFy
c2VycyI6W1siU0U6Okdvb2dsZSIsImRlZmF1bHQiLHsidHlwZSI6Im92ZXJyaWRl
IiwiaWQiOiJwYWdlY291bnQiLCJ2YWx1ZSI6MX0seyJ0eXBlIjoib3ZlcnJpZGUi
LCJpZCI6ImxpbmtzcGVycGFnZSIsInZhbHVlIjoxMH0seyJ0eXBlIjoib3ZlcnJp
ZGUiLCJpZCI6InVzZXByb3h5IiwidmFsdWUiOmZhbHNlfV1dLCJyZXN1bHRzRm9y
bWF0IjoiJHAxLnByZXNldCIsInJlc3VsdHNTYXZlVG8iOiJmaWxlIiwicmVzdWx0
c0ZpbGVOYW1lIjoiJGRhdGVmaWxlLmZvcm1hdCgpLnR4dCIsImFkZGl0aW9uYWxG
b3JtYXRzIjpbXSwicmVzdWx0c1VuaXF1ZSI6Im5vIiwicXVlcnlGb3JtYXQiOlsi
JHF1ZXJ5Il0sInVuaXF1ZVF1ZXJpZXMiOmZhbHNlLCJzYXZlRmFpbGVkUXVlcmll
cyI6ZmFsc2UsIml0ZXJhdG9yT3B0aW9ucyI6eyJvbkFsbExldmVscyI6ZmFsc2Us
InF1ZXJ5QnVpbGRlcnNBZnRlckl0ZXJhdG9yIjpmYWxzZX0sInJlc3VsdHNPcHRp
b25zIjp7Im92ZXJ3cml0ZSI6ZmFsc2V9LCJkb0xvZyI6Im5vIiwia2VlcFVuaXF1
ZSI6Ik5vIiwibW9yZU9wdGlvbnMiOmZhbHNlLCJyZXN1bHRzUHJlcGVuZCI6IiIs
InJlc3VsdHNBcHBlbmQiOiIiLCJxdWVyeUJ1aWxkZXJzIjpbXSwicmVzdWx0c0J1
aWxkZXJzIjpbXSwiY29uZmlnT3ZlcnJpZGVzIjpbXX19
4.18. I add a task, go to the Task Queue tab - but it's not there! Why?
Either a mistake was made when creating the task, or it has already been completed and moved to Completed.
4.19. It says the file is not in utf-8, but I didn't change it, it's already utf-8, what to do?
Check again. Also try to change the encoding anyway, for example using Notepad++.
4.20. In the result file everything is in one line, although I set a line break in the task - why?
In additional A-Parser settings, you need to use the line break CRLF (Windows).
But if you have already parsed without this option, then use a more advanced viewer for viewing, for example Notepad++.
4.21. How much time does it take to check query frequency on Yandex for 1,000 queries?
This indicator highly depends on task parameters, server characteristics, proxy quality, etc., so it's impossible to give a definite answer.
4.22. How do I configure the parser so the result is query-link?
Result format:
$p1.serp.format('$query: $link\n')
The result will be:
query: link 1
query: link 2
query: link 3
4.23. How do I re-parse failed queries and where are they stored?
In order for failed queries to be saved, you should select the corresponding option in the Queries block in the Task Editor. Failed queries are stored in queries\failed. You need to create a new task and specify the file with failed queries as the query file.
4.24. How to get rid of HTML tags when parsing text?
Use the Remove HTML tags option in the Results Builder.
4.25. How to make it so only domains are parsed?
Use the Extract Domain option in the Results Builder.
4.26. What is the maximum query file size that can be used in the parser?
The sizes of query and result files are not limited and can reach terabyte values.
4.27. Why, when I enter text in the queries field, does the parser give Queries length limited to 8192 characters?
This happens because the query length is limited to 8192 characters. To use longer queries, use files as queries.
4.28. What does Waiting threads - 3 mean?
This means that there are not enough proxies. Reduce the number of threads or increase the number of proxies.
4.29. In the test parse it says 596 SOCKS proxy error: Hello read error(Connection reset by peer) (0 KB) and doesn't parse, why?
This indicates non-working proxies.
4.30. What is the difference between result language and search country in the Google parser?
The difference is as follows: search country is the binding of results to a specific country. For example, if you are looking for buy windows with a binding to a specific country, priority will be given to sites offering to buy windows in that specific country. And result language is the language in which results should be displayed.
4.31. A certain site is not being parsed for me. What could it be?
Often the problem is that blocking occurs due to an old user agent on the server side. It is solved by a new user agent or the following code in the User agent parameter:
[% tools.ua.random() %]
4.32. Parser hangs, crashes. The line syswrite: No space left on device appears in the log
A-Parser lacks hard drive space. Free up more space.
4.33. My parser started giving none in results (or clearly incorrect result)
4.34. A window with the text Failed fetch news constantly appears
4.35. How to output the first n results of search results?
4.36. How to track a chain of redirects?
4.37. How to check if a link is indexed on the donor?
There is a separate parser for such purposes:  Check::BackLink.
More details in the discussion.
Check::BackLink.
More details in the discussion.
4.38. Parser crashes on Linux. The log contains such an entry: EV: error in callback (ignoring): syswrite() on closed filehandle at AnyEvent/Handle.pm line...
Most likely, you need to tune the number of threads as described in Documentation: Linux tuning for a large number of threads.
4.39. Where can I see all possible parameters for their use via API?
Getting an API request in the interface.
Also, you can generate a full task configuration in JSON. To do this, take the task code and decode it from base64.
4.40. I am downloading images using  Net::HTTP, but they are all corrupted for some reason. What should I do?
Net::HTTP, but they are all corrupted for some reason. What should I do?
1) Check the Max body size parameter - you might need to increase it. 2) Check the line break format in A-Parser settings: Additional settings - Line break.
To ensure the image is not corrupted, the UNIX format must be used.
4.41. How to get admin contact from WHOIS?
Such a task is easily solved using the Parse custom result function and a regular expression. Details in the discussion.
4.42. Regular expression for parsing phone numbers
4.43. Identifying sites without a mobile version
4.44. How to find out the name of the ns-server?
4.45. How to scrape links to Yandex cache?
4.46. How to scrape links to all pages of a site?
4.47. How to scrape title from a page?
4.48. How to scrape all sites in a given domain zone?
4.49. How to collect all urls with parameters?
4.50. How to filter results by several criteria and split them in the report?
4.51. How to simplify filter construction?
4.52. How to sort by files depending on the result?
4.53. Create new result directory every X number of files (English)
4.54. First steps working with WordStat
4.55. Collection of text blocks >1000 characters
4.56. Outputting a certain amount of text from a page
This is also solved using Template Toolkit. More details in the discussion.
4.57. Checking competition and title inclusion in Google
4.58. Filtering by the number of query occurrences in anchor and snippet
4.59. How to get article content in one line?
4.60. How to compare two string dates?
4.61. How to parse highlighted words from a snippet?
4.62. Example of a task using several parsers
4.63. How to shuffle lines in the result and how to output a random number of results?
4.64. How to sign the result using MD5?
4.65. How to convert a date from Unix timestamp to string representation?
4.66. Parse to level, how to parse with restriction?
4.67. Parser crashes on Linux when starting a task. The log contains such lines: Can't call method "if_list" on an undefined value at IO/Interface/Simple.pm...
It is necessary to execute the command in the console:
apt-get --reinstall --purge install netbase
4.68. Error Cannot init Parser: Error: Failed to launch the browser process! [0429/082706.472999:ERROR:zygote_host_impl_linux.cc(90)] Running as root without --no-sandbox is not supported...
You need to run A-Parser not as root. Specifically: from the root user, you need to create a new user without root privileges (if one exists, just use it) and then allow this user to interact with the A-Parser directory, then log in as the new user and run it from there.
Under the root user, create a user, you can follow this guide.
To allow the created user to interact with the A-Parser directory, you need to grant the user permissions. To do this, log in under the root user and grant permissions with the command:
chown -R user:user aparser
4.69. Error Cannot init Parser: Error: Failed to launch the browser process! [0429/102002.619437:FATAL:zygote_host_impl_linux.cc(117)] No usable sandbox! Update your kernel or see...
Under the root user, execute the command:
sysctl -w kernel.unprivileged_userns_clone=1
A-Parser restart is not required.
For CentOS 7, the solution is in this thread.
Under the root user, execute the command:
echo "user.max_user_namespaces=15000" >> /etc/sysctl.conf
Then restart sysctl with the command:
sysctl -p
4.70. Error JavaScript execution error(): Error: Failed to launch the browser process! /aparser/dist/nodejs/node_modules/puppeteer/.local-chromium/linux-884014/chrome-linux/chrome: error while loading shared libraries: libatk-1.0.so.0: cannot open shared object file: No such file or directory...
The error occurs due to the absence of libraries in the OS required for Chrome to function.
The list of required libraries for Chrome can be found in Chrome headless doesn't launch on UNIX.
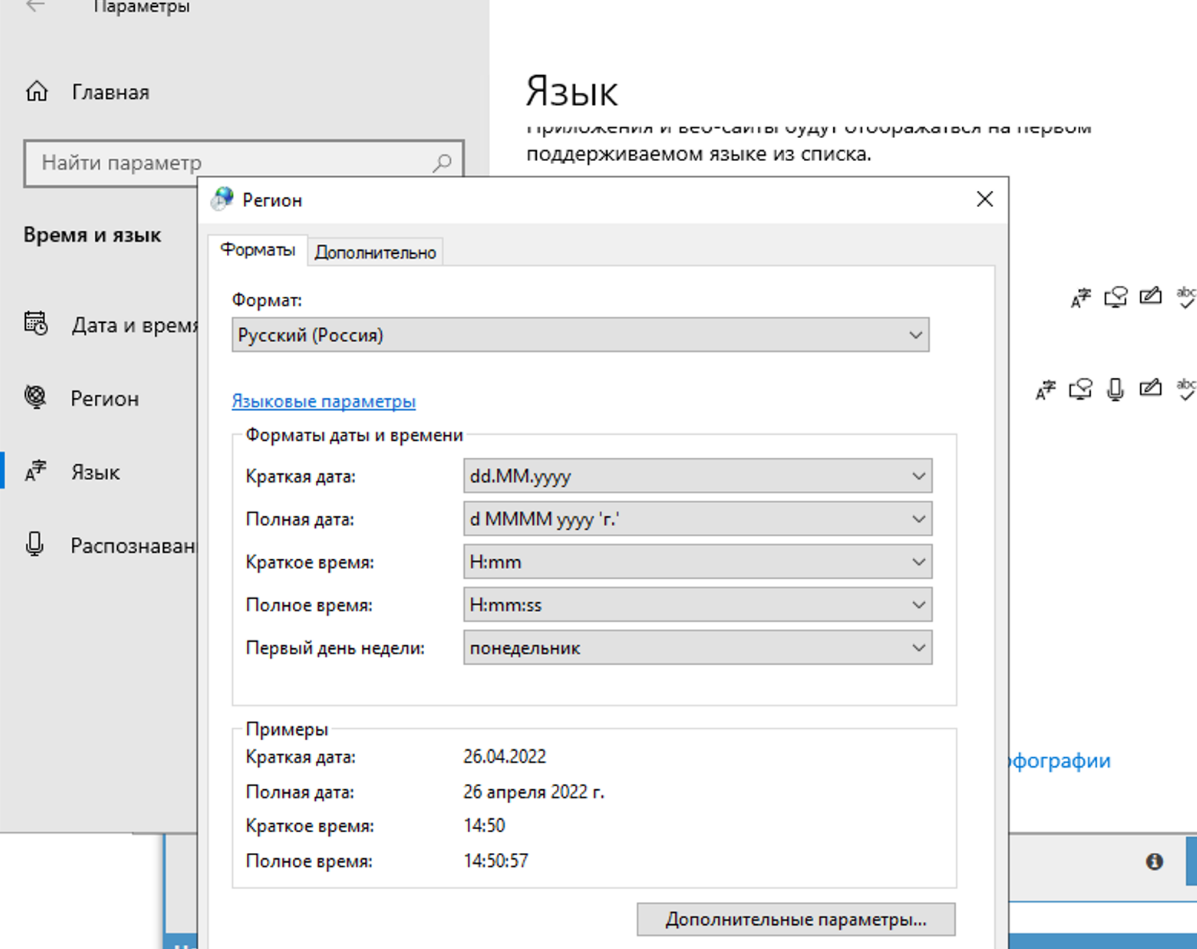
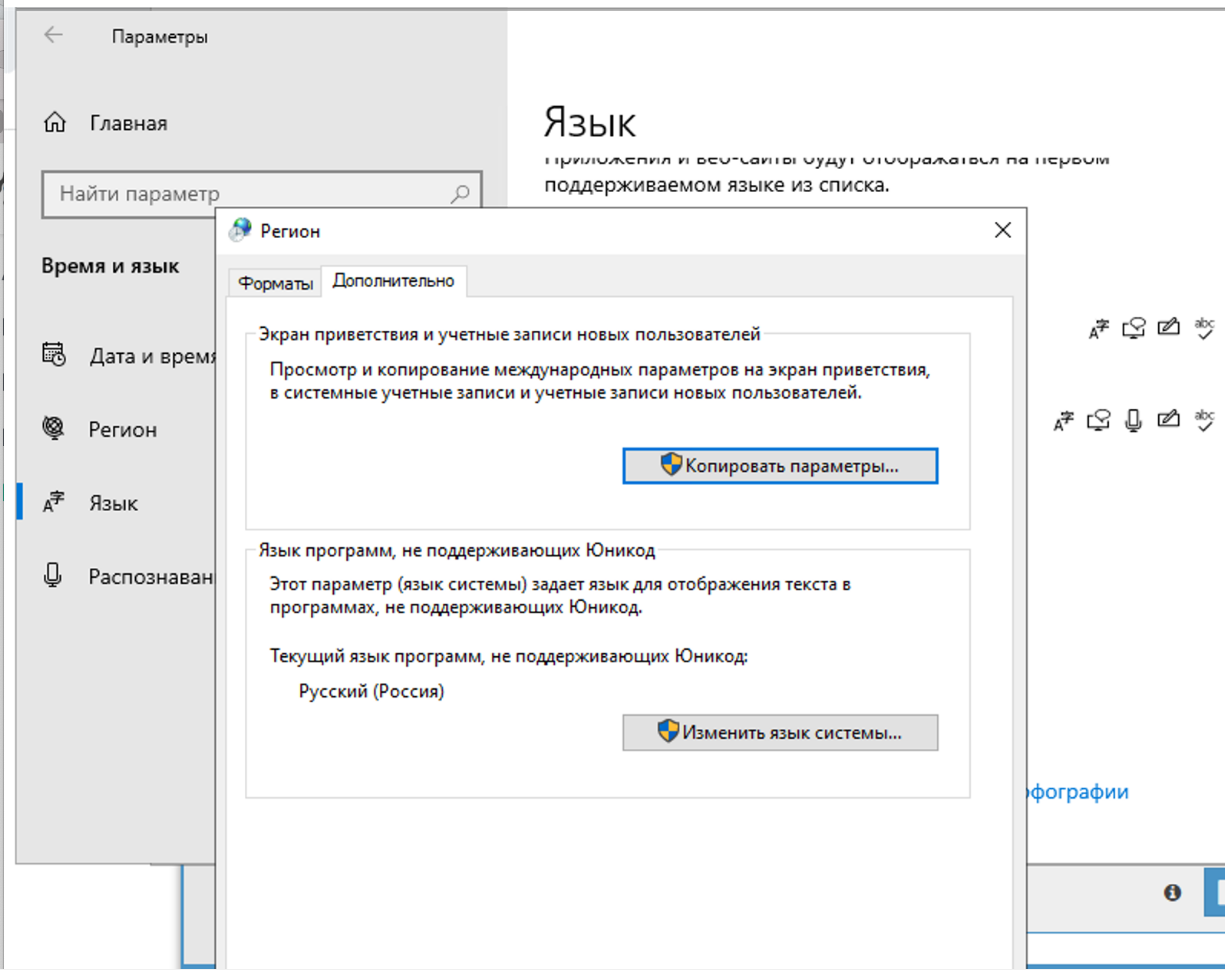
4.71. Why is the captcha not being solved? The log shows that A-Parser received question marks from XEvil instead of the captcha answer
In the region settings, you need to change it to Russian.
You should only change it on the advanced tab. This does not affect captcha solving, but there will be an encoding problem in Xumer itself if you change it in both places.