Rank::Curlie - checking website presence in the Curlie directory (DMOZ alternative)
Overview of the parser
Curlie is the largest and most comprehensive human-edited directory on the web. It is created and maintained by a vast community of volunteer editors from all corners of the world. Formerly known as DMOZ and the Open Directory Project (ODP).
Saving results is possible in any form and structure you need, thanks to the built-in powerful Template Toolkit templating engine, which allows applying additional logic to results and outputting data in various formats, including JSON, SQL, and CSV.
Collected data
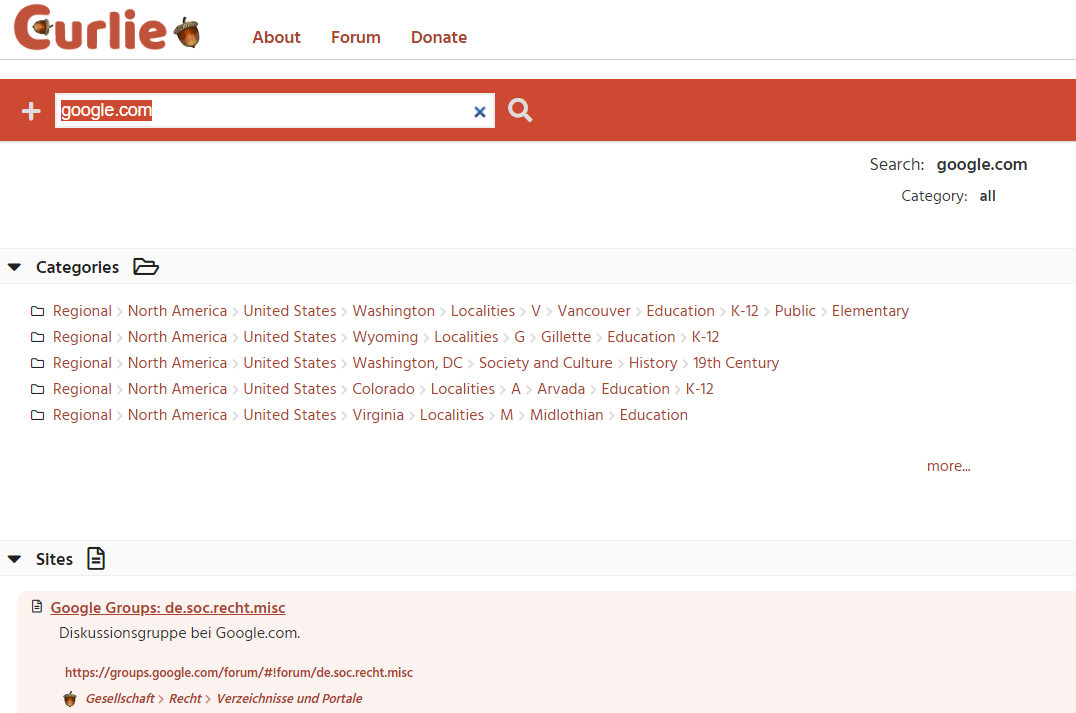
Data is collected from the curlie.org service
- Presence of the site in the Curlie directory (analogous to DMOZ)
Use cases
- Checking for the presence of a site in the curlie.org directory
Queries
As queries, you need to specify a list of domains, for example:
bing.com
learn.javascript.ru
trello.com
ellistalks.com
megastom.ru
Output results examples
A-Parser supports flexible result formatting thanks to the built-in Template Toolkit templating engine, which allows it to output results in any form, as well as in structured formats like CSV or JSON
Default output
Result format:
$query: $exists\n
The result displays the domain and its presence (1) or absence (0) in the curlie.org directory:
bing.com: 1
trello.com: 1
megastom.ru: 0
ellistalks.com: 1
learn.javascript.ru: 1
Output in CSV table
Result format:
[% tools.CSVline(query, exists) %]
Example result:
"trello.com",1
"bing.com",1
"ellistalks.com",1
"learn.javascript.ru",1
"megastom.ru",0