Telegram::GroupScraper - Data scraper for public Telegram groups
Parser overview
This parser collects message data from public groups in Telegram. The Telegram group/chat parser collects members who have posted in the group or for whom there is a service notification about joining the group. You can parse all content from the required groups, namely: text, images, video links, and obtain information about the publication date and author (name, profile link, avatar).
Its operation logic differs from other parsers because it automatically adds queries to iterate through all messages in the group. Due to this, this parser cannot be used together with any others in a single task.
Results can be saved in any format and structure you need, thanks to the powerful built-in Template Toolkit which allows applying additional logic to results and outputting data in various formats, including JSON, SQL, and CSV.
Parser use cases
🔗 User parsing
Parsing users from public Telegram groups
🔗 Parsing all messages
Parsing all messages from public Telegram groups
Collected data
Below are the data points that can be collected separately for public Telegram channels and Telegram groups.
What can be collected for Telegram channels
The following data is available only for open (public) Telegram channels:
- Message link
- Message text
- Message photo
- Message video
- Message date
What can be collected for Telegram groups
The following data is available only for open (public) Telegram groups:
- Message link
- Author's name
- Author's profile link
- Author's avatar
- Message text
- Message photo
- Message video
- Message date
- Members who posted in the group
- Members from service notifications about joining the group
Use cases
- Collecting a list of group members
- Collecting the content of all messages in a group
Queries
As queries, you must specify a link to a public (open) channel or group, for example:
https://t.me/a_parser
Output results examples
A-Parser supports flexible result formatting thanks to the built-in Template Toolkit, allowing it to output results in any form, as well as structured formats like CSV or JSON.
Default output
Result format:
$user_name($user_link): $message_text\n
Result example:
(https://t.me/aparser): To bypass the limit of 10 requests from one IP, you need to additionally parse key= from the main page
(https://t.me/aparser): I'll take a look now
(https://t.me/aparser): <a href="http://a-parser.com/threads/1795/" target="_blank" rel="noopener">http://a-parser.com/threads/1795/</a>
Output in CSV table
Result format:
[% tools.CSVline(query, user_link, message_date, message_text) %]
Result example:
https://t.me/a_parser,https://t.me/Forby403,2016-11-05T05:01:09+00:00,"Settings - Save window size"
https://t.me/a_parser,https://t.me/Forby403,2016-11-05T05:14:47+00:00,"I run 20 tasks with 300 threads each, with a dynamic limit of 1200, they complete much faster because they all work simultaneously and there are no bottlenecks when few requests (threads) remain"
https://t.me/a_parser,https://t.me/Forby403,2016-11-05T05:27:06+00:00,"well proxies too"
Results processing
A-Parser allows processing results directly during parsing; in this section, we have listed the most popular cases for the Telegram parser.
Filtering results by occurrence of words in message
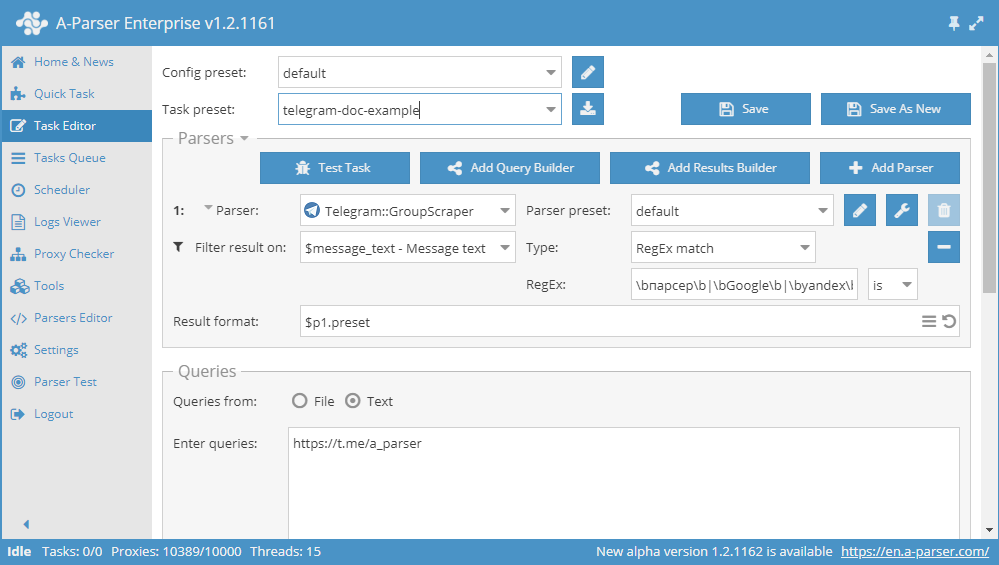
You need to add a filter and select $message_text - Message text in the dropdown list. Select type Regex matches.
In the regex field, enter the regex with the required words:
\bparser\b|\bGoogle\b|\byandex\b|\bparser\b|\bProxy\b|\bDorks\b
\b - word boundary
| - OR
is - regex flag
Download example
How to import an example into A-Parser
eJyVVN1v2jAQ/18sHjaJ8qFSacobRaLaxEpX6BOg6oovqVfH9myHgTL+952dkMC6
PewhVu53v/v2uWQe3Jt7sOjQO5asSmbiP0uYR4mZhfyK6+0V7iE3ElmXGbAObeCu
2LKmJMmd1YVZbC0YtETimEIhPeuWzB8MkrdUSB9V5D5oEpajc5Dhs8c9EWvCsmJb
zMFvXwnegSwCsl6/rIvB6DqN5yCco+ocRuSmRtYvv+i70zqTWAsHUBz3tfAfToIw
TFvSNcYTzgw+nVNHLak2gIZElWjjhVZUinDsuNmcOuGm2lKxhHfMsFd3v1EuYIdL
XfUPW3hK0j3koTEdDh6DtpdGRx8+9nxsKHAuQkSQVYQwsjbqkxI/YmOVJi79WoFu
anUeJx8dBPBwym7FOlFm5KKItt8qG5akIB12maNUp0CJ8D81ggYLXtt57ADhJdNq
LOUMdyhbWvR/WwjJ6X6NUzL6XBv+nTJ/5+PYlHceaof2p6UcGi9Rup1/ba24numM
KudhUFLkwpPsJrpQYTADAt8QTdOz+9CzXFtswnhbYBOc1smg4kRsJzY2LXRRxcVU
LsGtVqnI5pS/FRxPzEItaWfnaqLDRoayVCElTcXhY3s7xq6eQhCayt8ZT2KIUPlp
Y5nXWroviypVYwXdvpuQYE6NPI9au9yClE+Ps3MNa28UCa/eG5f0+76XYx+eq/eD
BUOPmaYbRWUdN83D0rxF5b+el6Q80si+u4fKIBQY6IRRp1zcseHxN9yRrow=
Possible settings
| Parameter | Default value | Description |
|---|---|---|
| Max empty posts | 1000 | This parameter specifies how many consecutive empty (non-existent) messages must occur for parsing of the current query to stop |
| Start message number | 1 | This parameter specifies the message number from which to start collecting messages in the Telegram chat |