SE::Yandex::Direct::Frequency - Frequency Check
Scraper Overview
Yandex Direct search query scraper. The Yandex Direct keyword scraper can automatically collect the number of impressions per query for the specified period, and scrape Yandex Direct search suggestions.
You can use automatic query multiplication, substitution of sub-queries from files, iteration over alphanumeric combinations and lists to get the maximum possible number of results. Using result filtering you can immediately clean the result, removing all unnecessary rubbish (by using negative keywords).
A-Parser functionality allows you to save scraping settings for the SE::Yandex::Direct::Frequency scraper for later use (presets), set a scraping schedule, and much more.
Results can be saved in the format and structure you need, thanks to the built-in powerful templating engine Template Toolkit which allows applying additional logic to the results and outputting data in various formats, including JSON, SQL and CSV.
Collected Data
- Number of impressions per query for the specified period
- Scraping additional keywords (suggestions)
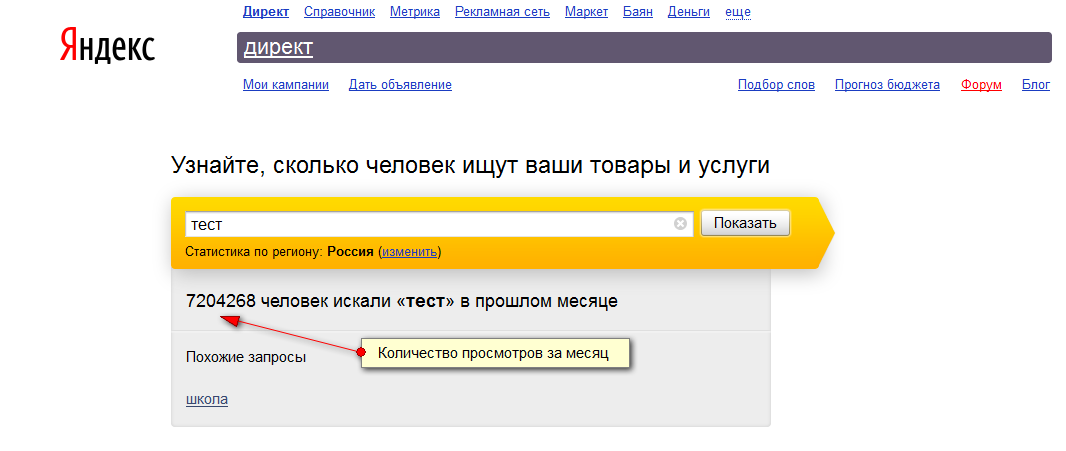
Capabilities
- Supports selection of search region (with subgroups)
- Supports selection of period (last month, specific month, quarter, year) (only when scraping with accounts)
Use Cases
- Assessing keyword traffic volume (frequency)
Accounts
To run the  SE::Yandex::Direct-Frequency scraper, you may need Yandex accounts. Accounts can be registered using the
SE::Yandex::Direct-Frequency scraper, you may need Yandex accounts. Accounts can be registered using the  SE::Yandex::Register scraper or simply add existing accounts to the
SE::Yandex::Register scraper or simply add existing accounts to the files/SE-Yandex/accounts.txt file in a [supported format](/parsers/se-yandex-register#account_for mat).
Alternatively, you can enable account registration "on the fly".
To use session authorization, the data string must be in this format:
[email protected];MAQT78Z31Rinx4H;{"answer":"qmfhsxdcrk","proxy":"185.104.120.45:3128","session_id":"3:1748440908.5.0.1748440867459:ZXBxpg:47e4.1.2:1|2191075974.41.2.2:41.3:1748440908|3:10308131.797655.5pfkoRZWgLJGntKTlcUhYdysNfk"}
Queries
When scraping with accounts, scraping occurs in
_test
"!city"
"city"_
Query substitutions
You can use built-in macros to automatically substitute sub-queries from files. For example, if we want to add a list of other words to each query, we specify several main queries:
essay
article
thesis
In the query format, we specify the macro for substituting additional words from the file Keywords.txt, this method allows you to significantly increase query variation:
{subs:Keywords} $query
This macro will create as many additional requests as there are in the file for each initial search query, resulting in a total of [number of initial queries (domains)] x [number of queries in the Keywords file] = [total number of queries] as a result of the macro execution.
For example, if the file Keywords.txt contains:
buy
cheap
As a result, the substitution macro will turn 3 main queries into 6:
buy essay
cheap essay
buy article
cheap article
buy thesis
cheap thesis
Result Output Options
A-Parser supports flexible result formatting thanks to the built-in templating engine Template Toolkit, which allows it to output results in arbitrary form, as well as in structured form, such as CSV or JSON
Exporting key frequency and suggestion list
Result format:
$query: $views\n$suggests.format('$key\n')
Example result:
online abstracts: 2771
technology abstract
download abstract topic
abstract training
order abstract
free abstract topic
English abstract language
free abstract download topic
essay test
find abstract
abstract test
abstract video
abstract translator
find work abstract
abstracts topic
Outputting key frequency
Result format:
$query: $views\n
Example result:
online abstracts: 2771
Output to CSV table
The built-in utility $tools.CSVLine allows you to create correct tabular documents, ready for import into Excel or Google Sheets.
Result format:
[% FOREACH i IN suggests; tools.CSVline(i.key); END %]
File name:
$datefile.format().csv
Initial text:
Suggestions
In the General result format the Template Toolkit templating engine is used to output elements of the key array suggests in a FOREACH loop.
In the result file name, you just need to change the file extension to csv.
For the "Initial text" option to be available in the Task Editor, you need to enable "More options". In "Initial text", write the column names separated by commas and make the second line blank.
Saving in SQL format
Result format:
[% FOREACH suggests; "INSERT INTO serp VALUES('" _ query _ "', '" _ key _ "')\n"; END %]
Example result:
INSERT INTO serp VALUES('online abstracts', 'technology abstract')
INSERT INTO serp VALUES('online abstracts', 'download abstract topic')
INSERT INTO serp VALUES('online abstracts', 'abstract training')
INSERT INTO serp VALUES('online abstracts', 'order abstract')
INSERT INTO serp VALUES('online abstracts', 'free abstract topic')
INSERT INTO serp VALUES('online abstracts', 'English abstract language')
INSERT INTO serp VALUES('online abstracts', 'free abstract download topic')
INSERT INTO serp VALUES('online abstracts', 'essay test')
INSERT INTO serp VALUES('online abstracts', 'find abstract')
INSERT INTO serp VALUES('online abstracts', 'abstract test')
INSERT INTO serp VALUES('online abstracts', 'abstract video')
INSERT INTO serp VALUES('online abstracts', 'abstract translator')
INSERT INTO serp VALUES('online abstracts', 'find work abstract')
INSERT INTO serp VALUES('online abstracts', 'abstracts topic')
...
Dump results to JSON
Общий формат результата:
[% IF notFirst;
",\n";
ELSE;
notFirst = 1;
END;
obj = {};
obj.totalcount = p1.totalcount;
obj.suggests = [];
FOREACH item IN p1.results;
obj.suggests.push(item.suggest);
END;
obj.json %]
Начальный текст:
[
Конечный текст:
]
Example result:
[{"suggests":["technology abstract","download abstract topic","abstract training","order abstract","free abstract topic","English abstract language","free abstract download topic","essay test","find abstract","abstract test","abstract video","abstract translator","find work abstract","abstracts topic"],"views":"2771"}]
For the "Initial text" and "Final text" options to be available in the Task Editor, you need to enable "More options".
Result Processing
A-Parser allows you to process results directly during scraping. In this section, we provide the most popular use cases for the SE::Yandex::Direct::Frequency scraper
Selecting a period for a year, quarter, or specific month
To specify the period, you need to use the option Report period and select the period from the dropdown list.
Download example
How to import the example into A-Parser
eJyFVG1v0zAQ/iuV1Q8glapj3Qf8rStUApV1rJvQVCrk1Zdi5tie7ZRVUf47d06a
tAPBl5Pv7bnnXpKSRREew7WHADEwviqZS2/G2fID5/fCSHjm/L3ysImczzw8FWA2
+96b3lcVf/TuQfieA6+sZAPmhA/gCWf173SMlZCJQkc2KFncO8CCdgfeKwnoVBL1
FnYndIEB5cHC2R7LUr2kfzdFjjZTaM2qar0eMGwBocPM+lxQK313Nmz6ap1LsYNb
i85MaejMM9SuRE58+lJEIO8wS0CvXg/jMyEIKVVU1ghdV6CGu6p3Rj0RXWYsxuLT
Kwgzb4ljhARAxv2B3Yr1k84Qoki5X+ocxjOhAwxYQKozgUTkS4+K4EW0fuGIT6AZ
WTPReg470F1Ywr8slJa4nUmGSR+bxL+HLP7AqNr2jkvhwn555NCiJO1y8bnLknZu
t4dhaJWriHqY2sLQYkZofARw7cyuKCy3HtoyDXJTHS/VgaET6FY2cZ3ppI2TtZwa
N9ZkartoLu4QWZhb/BwWZmpzp4H6oqPCtQS46c5jEpo1kNIRfJk8TSWQVnvpLFqr
w6dlTdXh7TJ+QQRznORx1QZyI7S+u5kfe1h3Uqh8K0bj8Yjk+UV6j4/etT3J8dsk
H3rJBEnKJB+6oPN3tZ1R4QhbiyeJY6nW7Xfd/ibK/3zdvKxw9T/DdZ1Hc6IstOHA
A+6V8bPqNzmXjXA=
Filtering results (using negative keywords)
By using negative keywords, you can immediately remove results that you don't need. Similarly, you can use the filter to keep only those results that contain the desired words.
Download example
How to import the example into A-Parser
eJy9Vltv2jAU/ivIqtRVYhUQUNu8td2QNnWj6+Vhomgy5IR6NXZqO6yI8t937ITY
lJWOauuLsc/lO9+5mHhODNV3+lyBBqNJ3J+TzO1JTC4/xvF3KhJ4iOMPTMHIxHFX
wX0OYjSrva91GTegavBAJxkHUicZVRqURelvdkbbBFKac0Pqc2JmGWA4OQWlWGKB
WILnDBSTCZ6mlOdoMF9KYjKRwtzagE7wQ+QTEjcWi+exxiA9UJ+0Wh0yCMxTlwla
YOqWFJrofDwGjSWpkzuYkUG9NLoqPBQIaSbUjG49LgqThJlHxjmMKX/UGRVMWwOZ
GSYFWpANHFOpELBk4EF3lkz2C4N3uztI6OZG7O6RxWCw5Ky7TmsdsuZ+2cNKeUmn
cCWLTMGLsYPwlU5cmIQasNplmL1982ARqM0J2VNeRLDt9VGvBbt3NLVRTIzRHo+K
ge4qiU0hBhyIFc6WDPtkx51tUXPn/63wIbFROdSJRrZdilySSpFSrlHDsAPUSNVz
BdV2KKQ45vwMpsC9mYM/yRlPcByPU3T6VDr+2aS3hrGoMgxDYcd+KeRQobjTSe+L
90rkmRxj4skQ0+Zswgye9anMhe1Nw40TZFXZvtq5nEgFVZgSuYyOFzMDYcfDd+04
86KVNFY6syocSZGyca8cuaVlLq7w9vfEqbQ32OYlcs6xKxou/IQc67IN9uAJPnU+
dSFs6surTYyUXH++LKhmeFdJ3LEEJ1jJMGoJOaKcX1+chRriJwoPN3mj3W7YNeq4
fTvYF3K3tltuHdacCNyauHXojaKjUi7cL3Uukdunbj0MoEa1LWKLv7et+RiluhOw
hYBzsY8CZun2gZo+1VJx4AGj1loFR2v8olFpJAJWTV+7EjDMogDvbF3B6CBoVsC5
kLeHmzlvE6gZ6JvBBAyfghcZlaGPtgj0Uh0bQb2iIPahn9SV5h2+kkG6VkD6xjX4
1yNYAsIaVLJ5EMM711yZhiTg0AmmvO1B3vxfYZVhK0gnAIlg+9FP1/SdIESQ+Ept
6faBXlnVRjCcEJSl8Z9KX7B5duaI/UoZGEt8vuA3dDGoXr3VE3r+wts3nuNLlfzU
54Wf/ahaL5Th11m7d2Jz8RvgGZAl
See also: Result Filters
Available Settings
| Parameter Name | Default Value | Description |
|---|---|---|
| Region | Russia | Search region |
| Use Yandex accounts | ☐ | Determines whether to use Yandex accounts |
| AntiGate preset | default | Scraper Preset Util::AntiGate. You must pre-configure the scraper  Util::AntiGate - specify your access key and other parameters, and then select the created preset here Util::AntiGate - specify your access key and other parameters, and then select the created preset here |
| AntiGate preset for Login | default | AntiGate preset for login. You must pre-configure the scraper Util::AntiGate with parameters, and then select the created preset here |
| Report period | Month: last 30 days | Select period (last month, specific month, quarter, year). Available only when scraping with accounts |
| Remove bad accounts | Always, except wrong login/password | Automatic removal of "bad" accounts: Always - always remove. Always, except wrong login/password - always remove, except when Yandex reported incorrect login/password. This is because Yandex may give such a message when the IP is banned for a perfectly working account, so optionally you can leave such accounts for reuse. Never - never remove. Regardless of the selected option, accounts are not removed in case of proxy/browser errors |
| Wait new accounts in "accounts.txt" | 0 | Wait time for new accounts to appear in accounts.txt |
| Authorization method | HTTP | Authorization method: HTTP - fast, low resource requirements. Chrome - slow, high resource requirements, theoretically may extend account lifetime |
| Use sessions | ☑ | Use sessions |
| Do not reset session if authorization passed | ☑ | Do not reset session on errors if the scraper is already authorized |
| Accounts | Only from "accounts.txt" | Select account management method: Always auto register - always automatically register accounts "on the fly", requires selecting a configured preset in the SE::Yandex::Register preset parameter. Auto register if no more in "accounts.txt" - first use existing accounts from accounts.txt, and if they run out - use automatic registration "on the fly", for which you must select a configured preset in the SE::Yandex::Register preset parameter. Only from "accounts.txt" - use only existing accounts from accounts.txt, and if they run out - wait the specified time (Wait new accounts in "accounts.txt" parameter) for new ones to appear. Only by session_id from "accounts.txt" - authorization by cookies. |