HTML::TextExtractor - Parsing Content (Text) from a Website
Overview of the scraper
 HTML::TextExtractor scrapes text blocks from the specified page. This content scraper supports multi-page scraping (page navigation). It has built-in means to bypass CloudFlare protection and also the ability to select Chrome as the engine for scraping content from pages where data is loaded by scripts. It is capable of speeds up to 2000 requests per minute – which is 120 000 links per hour.
HTML::TextExtractor scrapes text blocks from the specified page. This content scraper supports multi-page scraping (page navigation). It has built-in means to bypass CloudFlare protection and also the ability to select Chrome as the engine for scraping content from pages where data is loaded by scripts. It is capable of speeds up to 2000 requests per minute – which is 120 000 links per hour.Scraper use cases
Text parsing via Chrome using lingualeo.com as an example
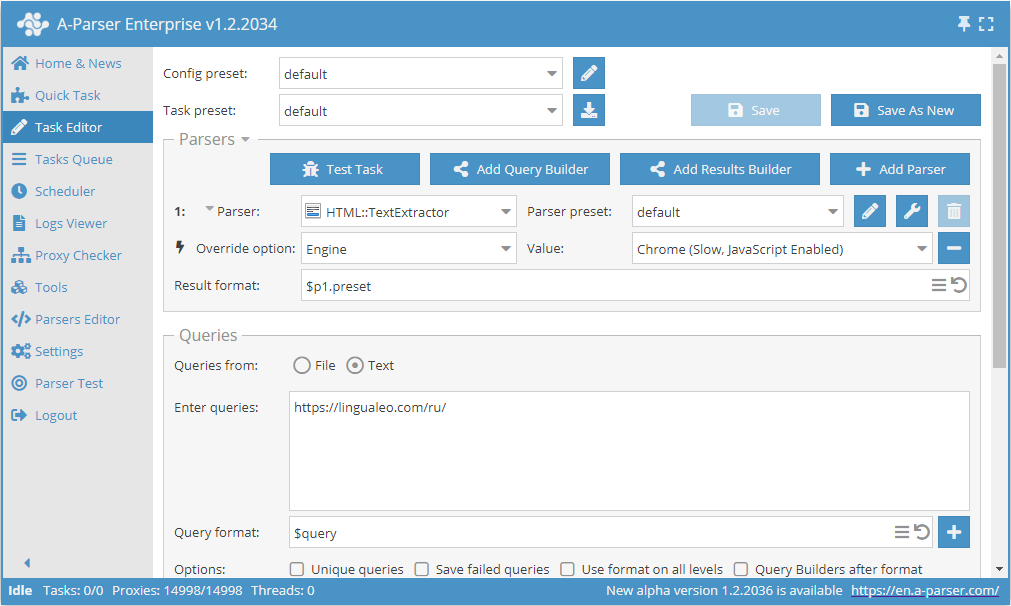
- Add the option Engine, and select the engine
Chrome (Slow, JavaScript Enabled). - As the query, specify the link to the website from which text needs to be scraped.
This option can be useful in cases where the website loads the main text via scripts during page loading, and the result is missing or incomplete when using the HTTP (Fast, JavaScript Disabled) engine.
Download example
How to import the example into A-Parser
eJxtU01v2zAM/S9EDhsQJO1hF9/SYME6pHXXpqcgB8GmXa2ypOkjS2Hkv+/Jce2k
680kHx8fxeeWgvCv/sGx5+Ap27Zku2/KqORKRBVoSlY4zy6Vt/Rjc7fOsg0fwvdD
cKIIxgExYFsKb5bRbfbsnCwZRVkiZl1LnaK9UDEBihdnGqbjbjcljES3XxnXiDR6
Yq9nvY6h+CT2vDEoVlLxmF4huhdNYpyUInCqzqqO6MvXWTgkBlGWMkijhTpNSJuM
U5+1/NMp8sFJXQOP0En2KwhEOnBHkpJv7wq3NOliAk3s+n+deigLLvKUPNSuBLSU
Q6ESyqMiAzuBV8ttkoR8S0YvlFrzntUI6+hvolQlXn5Roem2b/wckv/HcRw2PB+F
s/x10DCwdNFNfjd2lWZtaiyuDdZWspEBsV+aqNNtrpB8ZbbDs90nWGMcD2N65n46
zGVZJw+MV1vYMXWxxsVlLpOF0ZWs895X78ioN3BwrpemsYrTXjoqhat4fhwdsvD9
GVIwCvzYvOxGXHg/GKP8z6eTVOskHPgtCWzwkudTe8pCKPX8uD6v0OgoBC8hWJ/N
5wpWi0KxmRWmmbs4p9QcuDZwFVY77ob/bvg720//vqw94mi//cMJnTZMWOTwVB4X
oez6+A9VbWHX
Text parsing with page navigation using news as an example
The results are saved in the directory aparser/results/example/textextractor in a separate file for each query. The query sequence number is used as the file name.
- Add the option Check next page, and specify the regex
(forum\/news\/page-\d+)"[^>]+>Forward. - Add the Page as new query option.
- Change File name to
example/textextractor/${query.num}.txt. - As the query, specify the link to the first news page on A-Parser:
https://a-parser.com/forum/news/.
Download example
How to import the example into A-Parser
eJx1VN1v2jAQ/18sHjaVEtjoSx4qUVS0TRRoS58Ik6zkQj0c27UdPhTlf9/ZCQmw
7sXJne/jd7+7c0EsNVuz0GDAGhKuCqL8PwnJ44FmikMYLuFgHw9W09hKHYYzFBd0
A6RLFNUGtPNbkR/Lp+mVLVokkNKcW9ItiD0qwLBSWSaFwTuWoBi/Q7w9C7mjPHdm
X1Kp8yyKAgF7gx+F17dRlNx8jcjq9/365j7K+8PBN3d+T/15585h3513A68ZYkCa
JMxlpJyExWW6KcuYq7RPyvK/AF3ikZnB/jkHfWwRWp3DdfQtgPJmU9gBavpluV53
CTKKHJiJ1Bl1+Tpq0Ktpbi5f6Q6WEi9TxqFVT1Ca0czhgqofgUX0cKI46BQfLmFP
5FnZswd7UXGV0fWnRfEm2IdnWEi0dc4MzETLDFUubq08ntCuSMfLBEPk3ve58iFh
SrlBDgxCn1AEmlzfMAuaIsp5TSlSJMWIc09Pa+bjP+SMJzhMoxSdftaOn5vM/4lR
NuWdp9qB3mvE0ETx0sP8qfVK5FRuTmRwNw8om7HMRTUYXd/ThrOZM8ukhiZNHbnO
joukQLixaVs4Uq3qooyLtlwqYylStpljAZolcLLMxRK3dS7G0g2Cq0vknGNbDLy0
4zIydRuc0AK8dh77FAirWVFipeTm12sFVWmG43jnAGbI5HnWOmRMOX97mZ7fkHak
UHi3VpkwCOht9VD0YpkFfq/9VgfExbCwkThdWGG5bl6U5kEqPn1XwgIXlvwxi8ra
FepsUYeMGWwMCQflX6y1tO0=
Collected data
- Scrapes text blocks from the specified page
- Array with all collected pages (used when the Use Pages option is enabled)
Capabilities
- Multi-page text scraping (page navigation)
- Automatic cleaning of text from HTML tags
- Ability to set a minimum length for the text block
- Optional removal of anchor links from the text
- Supports gzip/deflate/brotli compression
- Detection and conversion of website encodings to UTF-8
- CloudFlare protection bypass
- Engine selection (HTTP or Chrome)
Use cases
- Scraping text content from any website
Queries
Queries must be the links to the pages from which text blocks need to be scraped, for example:
https://a-parser.com/
Examples of result output
A-Parser supports flexible result formatting thanks to the built-in templating engine Template Toolkit, which allows it to output results in an arbitrary form, as well as in structured formats like CSV or JSON
Default output
Result format:
$texts.format('$text\n')
Result example:
Hello, Super Team of Highly Professional Experts! Thank you for the opportunity to study Spanish, Turkish, and Portuguese! I wish you further expansion of your capabilities! Inspiration and Creativity! And please add the ability to learn German and French!”
I have been using lingualeo for many years, I first started studying when there was no app at all, only the website existed) Thank you to the developers, keep up the good work, with creativity and great love for your cause)
Technical English for IT: dictionaries, textbooks, magazines
Learn languages online Learn English online Learn Vietnamese online Learn Greek online Learn Indonesian online Learn Spanish online Learn Italian online Learn Chinese online Learn Korean online Learn German online Learn Dutch online Learn Polish online Learn Portuguese online Learn Serbian online Learn Turkish online Learn Ukrainian online Learn French online Learn Hindi online Learn Czech online Learn Japanese online
Possible settings
| Parameter name | Default value | Description |
|---|---|---|
| Min block length | 50 | Minimum length of the text block in characters. |
| Skip anchor text | ☐ | Whether to skip anchors in the text. |
| Ignore tags list | Option to specify tags to ignore. Example: div,span,p | |
| Good status | All | Select which server response is considered successful. If the scraper receives a different response from the server, the query will be retried with a different proxy. |
| Good code RegEx | Ability to specify a regular expression to validate the response code. | |
| Method | GET | Request method. |
| POST body | Content to send to the server when using the POST method. Supports variables: $query – request URL, $query.orig – original query, and $pagenum - page number when using the Use Pages option. | |
| Cookies | Ability to specify cookies for the request. | |
| User agent | `_Automatically substitutes the user-agent of the current Chrome version_ | User-Agent header when requesting pages. |
| Additional headers | Ability to specify arbitrary request headers with support for templating features and using variables from the query builder. | |
| Read only headers | ☐ | Read headers only. In some cases, this saves traffic if content processing is unnecessary. |
| Detect charset on content | ☐ | Recognize encoding based on page content. |
| Emulate browser headers | ☐ | Emulate browser headers. |
| Max redirects count | 7 | Maximum number of redirects the scraper will follow. |
| Max cookies count | 16 | Maximum number of cookies to save. |
| Bypass CloudFlare | ☑ | Automatic CloudFlare check bypass. |
| Follow common redirects | ☑ | Allows http <-> https and www.domain <-> domain redirects within a single domain, bypassing the Max redirects count limit. |
| Engine | HTTP (Fast, JavaScript Disabled) | Allows choosing the HTTP engine (faster, no JavaScript) or Chrome (slower, JavaScript enabled). |
| Chrome Headless | ☐ | If this option is enabled, the browser will not be displayed. |
| Chrome DevTools | ☑ | Allows using tools for Chromium debugging. |
| Chrome Log Proxy connections | ☑ | If this option is enabled, information about chrome connections will be output to the log. |
| Chrome Wait Until | networkidle2 | Determines when a page is considered loaded. More about the values. |
| Use HTTP/2 transport | ☐ | Determines whether to use HTTP/2 instead of HTTP/1.1. For example, Google and Majestic immediately ban if HTTP/1.1 is used. |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | CF bypass via Chrome. |
| Bypass CloudFlare with Chrome Max Pages | Max number of pages when bypassing CF via Chrome. |